| Name | Type | Default | Description |
|---|
| jsx | Boolean | false | Support JSX syntax |
| range | Boolean | false | Annotate each node with its index-based location |
| loc | Boolean | false | Annotate each node with its column and row-based location |
| tolerant | Boolean | false | Tolerate a few cases of syntax errors |
| tokens | Boolean | false | Collect every token |
| comment | Boolean | false | Collect every line and block comment |
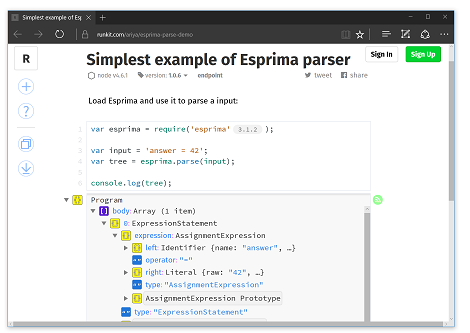
The previous chapter, [Getting Started](getting-started.html), already demonstrates the simplest possible example of using Esprima parser. To use it as the basis for further experiments, use Runkit and tweak the existing demo notebook: [runkit.com/ariya/esprima-parse-demo](https://runkit.com/ariya/esprima-parse-demo).
## Distinguishing a Script and a Module
With ES2015 and later, a JavaScript program can be either [a script or a module](http://www.ecma-international.org/ecma-262/6.0/index.html#sec-ecmascript-language-scripts-and-modules). It is a very important distinction, a parser such as Esprima needs to know the type of the source to be able to analyze its syntax correctly. This is achieved by choosing `parseScript` function to parse a script and `parseModule` function to parse a module.
An example of parsing a script:
```js
$ node
> var esprima = require('esprima')
> esprima.parseScript('answer = 42');
Script {
type: 'Program',
body: [ ExpressionStatement { type: 'ExpressionStatement', expression: [Object] } ],
sourceType: 'script' }
```
An example of parsing a module:
```js
$ node
> var esprima = require('esprima')
> esprima.parseModule('import { sqrt } from "math.js"');
Module {
type: 'Program',
body:
[ ImportDeclaration {
type: 'ImportDeclaration',
specifiers: [Object],
source: [Object] } ],
sourceType: 'module' }
```
Failing to choose the correct parsing function can lead to a _mistaken_ observation that Esprima does not support a certain syntax. Take a look at this example:
```js
$ node
> var esprima = require('esprima')
> esprima.parseScript('export const answer = 42');
Error: Line 1: Unexpected token
```
Instead of producing the syntax tree, the parser throws an exception. This is the correct behavior, an `export` statement can only be part of a module, not a script. Thus, the parser properly determines that such a source program is invalid.
*Note*: In the previous versions (Esprima <= 3.1), there was a single parsing function, `parse`. To distinguish between parsing a script and a module, the `sourceType` property in the configuration object needs to be specified, either as `"script"` (also the default value) or `"module"`. While this `parse` function is still supported in Esprima 4 for API backward compatibility, its usage is highly discouraged and the support for it may be removed in a future version.
## JSX Syntax Support
[JSX](http://facebook.github.io/jsx/) is a syntax extension to JavaScript, popularly known to build web applications using [React](https://facebook.github.io/react/). JSX is not part of any [official ECMAScript specification](http://www.ecma-international.org/publications/standards/Ecma-262.htm). Application code using JSX is typically preprocessed first into standard JavaScript.
Esprima parser fully understands JSX syntax when `jsx` flag in the parsing configuration object is set to true, as illustrated in the following example:
```js
$ node
> var esprima = require('esprima')
> esprima.parseScript('var el=