# 0001: Wildcard Field Migration
- Stage: **3 (finished)**
- Date: **2021-08-13**
Wildcard is a data type for Elasticsearch string fields introduced in Elasticsearch 7.9. Wildcard optimizes performance for queries using wildcards (`*`) and regex, allowing users to perform `grep`-like searches without the limitations of the existing
text[0] and keyword[1] types.
This RFC focuses on migrating a subset of existing ECS fields, all of which currently use the `keyword` type, to `wildcard`. Any net new fields introduced into ECS and are well-suited are encouraged to use `wildcard` independently of this RFC.
The objectives of this migration:
* Leverage the improved searching using `wildcard` of regular expressions and leading wildcard on high-cardinality fields. Wildcard excels when searching for something in the middle of strings when there are many unique values to evaluate. It also addresses issues with the partial matching of string values important to [security use cases](https://socprime.com/blog/elastic-for-security-analysts-part-1-searching-strings/).
* Remove security blindspots caused by `keyword` field size limits (`ignore_above`) and the Lucence hard limit (32k for each value) when dealing with large event values or messages.
* Potentially less disk usage for high-cardinality fields
* Potentially simpler search expressions
## Fields
### Identified Wildcard Fields
For a field to use wildcard, it will require changing the field's defined schema `type` from `keyword` to `wildcard`. The following fields are candidates for `wildcard`:
The following fields are the identified candidates for migrating to `wildcard`:
| Field Set | Field(s) |
| --------- | -------- |
| [`error`](0001/error.yml) | `error.stack_trace` |
| [`http`](0001/http.yml) | `http.request.body.content`
`http.response.body.content` |
| [`process`](0001/process.yml) | `process.command_line` |
| [`registry`](0001/registry.yml) | `registry.data.strings` |
| [`url`](0001/url.yml) | `url.full`
`url.original`
`url.path` |
The complete set of proposed field definitions are in the [rfcs/text/0001/](0001/) directory.
### Example definition
Here's an example of applying this change to the `process.command_line` field:
**Definition as of ECS 1.10.0**
Schema definition:
```yaml
- name: command_line
level: extended
type: keyword
short: Full command line that started the process.
...
multi_fields:
- type: text
name: text
```
Mapping definition:
```json
{
"mappings": {
"properties": {
"command_line": {
"fields": {
"text": {
"norms": false,
"type": "text"
}
},
"ignore_above": 1024,
"type": "keyword"
}
}
}
}
```
**Example of the proposed change**
Schema definition:
```yaml
- name: command_line
level: extended
type: wildcard
short: Full command line that started the process.
...
multi_fields:
- type: text
name: text
```
Mapping definition:
```json
{
"mappings": {
"properties": {
"command_line": {
"fields": {
"text": {
"norms": false,
"type": "text"
}
},
"type": "wildcard"
}
}
}
}
```
**Note**: the existing `text` data type multi-field will remain if there is a need to support tokenized searches.
## Usage
Wildcard is well-suited for cases requiring partial matching of string values across long unstructured or semi-structured fields. Often, machine-generated events, such as logs, metrics, and traces, aren't well suited for the analysis applied on `text` fields. Using `keyword` allows for exact value searching and introduces filtering, sorting, and aggregations. Keyword fields also support regex and wildcard queries, however, the field's search performance can vary, depending on the query (for example, leading wildcard) and the cardinality of the data.
Often ECS approaches semi-structured fields by breaking their values down into structured ones. These structured fields then enable better use of keyword fields' characteristics. For example, a URL can break down into its constituent parts: scheme, domain, port, path, etc., and those parts can, in turn, map to unique fields. However, not all fields are structured enough for this approach. Wildcard fields can work if a value doesn't have an established structure or can't be tokenized to accommodate all use cases.
In the security discipline, threat hunting searches and detection rules often rely on `grep`-like wildcard and regex patterns. Many other security platforms with search capabilities support wildcard and regex in this way. It often can be confusing to security practitioners trying to adopt their detections and techniques to Elastic. These users require detailed pattern-matching operations that perform consistently well across large data sets. Wildcard provides another capability to address this challenge.
Finally, wildcard support an unlimited character field size. Elasticsearch keyword fields default to a maximum string size of 256 characters which ECS ups to 1024 using `ignore_above`. A keyword field's size cannot increase infinitely due to Lucene's max limit of 32766 bytes for a single term. Due to how wildcard strings are indexed, they do not share this limitation. Wildcard is preferred over keyword when very long strings (>32kB) need to be indexed.
### Comparison with keyword
The following table is a comparison of `wildcard` vs. `keyword` [2]:
| Feature | Keyword | Wildcard |
| ------- | ------- | -------- |
| Sorting speeds | Fast | Not quite as fast (see *1) |
| Aggregation speeds | Fast | Not quite as fast (see *1) |
| Prefix query speeds (foo*) | Fast | Not quite as fast (see *2) |
| Leading wildcard queries on low-cardinality fields (*foo) | Fast | Slower (see *3) |
| Leading wildcard queries on high-cardinality fields (*foo) | Terrible | Much faster |
| Term query. Full value match (foo) | Fast | Not quite as fast (see *2) |
| Fuzzy query | Y (see *4) | Y |
| Regexp query | Y (see *4) | Y |
| Range query | Y (see *4) | Y |
| Supports highlighting | Y | N |
| Searched by "all fields" queries | Y | Y |
| Disk costs for mostly unique values | high (see *5) | lower (see *5) |
| Dist costs for mostly identical values | low (see *5) | medium (see *5) |
| Max character size for a field value | 256 for default JSON string mapping (1024 for ECS), 32766 Lucene max | unlimited |
| Supports normalizers in mappings | Y | N |
| Indexing speeds | Fast | Slower (see *6) |
1. Somewhat slower as doc values retrieved from compressed blocks of 32.
2. Somewhat slower because approximate matches with n-grams need verification.
3. Keyword field visits every unique value only once, but wildcard field assesses every utterance of values.
4. If "allow expensive queries" is enabled.
5. Depends on common prefixes - keyword fields have common-prefix-based compression, whereas wildcard fields are whole-value LZ4 compression.
6. Will vary with content, but a test indexing weblogs took 499 seconds vs. keyword's 365 seconds.
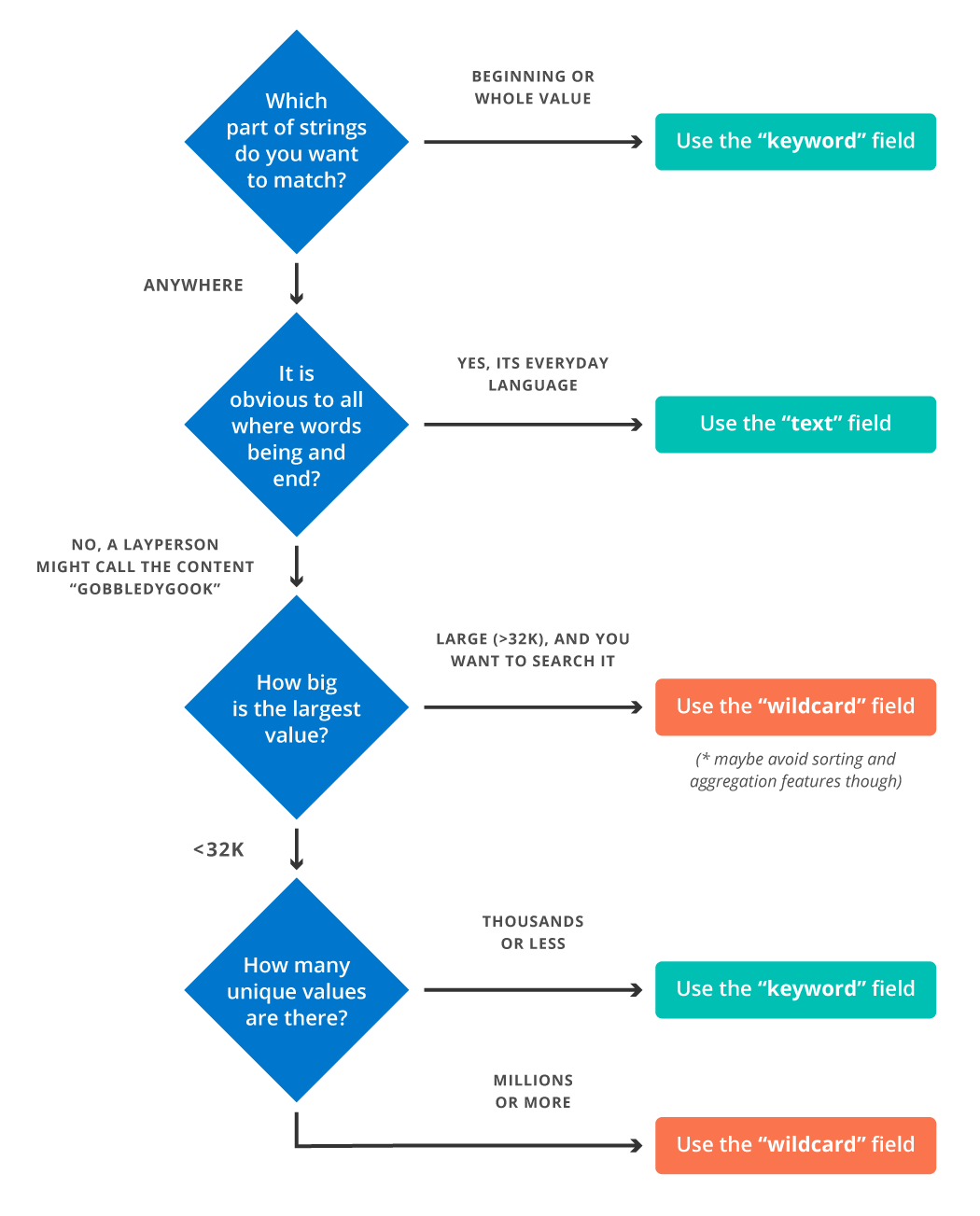
### Decision Flow
Since deciding between `wildcard` and `keyword` involves weighing trade-offs, this workflow is a visual to help assess when choosing `wildcard` may provide an advantage [2].
 ### Use Cases
The following sections detail use cases which could benefit using the `wildcard` type.
#### Stack traces
Program stack traces tend to be well-structured but with long text and varied contents. There are too many subtleties and application-specific patterns to map all of them accurately with ECS' field definitions. Better performing wildcard searches can help users formulate their queries easier and with a less significant performance hit.
Looking at the following example of a stack trace:
```java
bootstrap method initialization exception
at java.base/java.lang.invoke.BootstrapMethodInvoker.invoke(BootstrapMethodInvoker.java:194)
at java.base/java.lang.invoke.CallSite.makeSite(CallSite.java:315)
at java.base/java.lang.invoke.MethodHandleNatives.linkCallSiteImpl(MethodHandleNatives.java:259)
at java.base/java.lang.invoke.MethodHandleNatives.linkCallSite(MethodHandleNatives.java:249)
at org.elasticsearch.client.RestHighLevelClient.parseEntity(RestHighLevelClient.java:1883)
at org.elasticsearch.client.RestHighLevelClient.lambda$performRequestAndParseEntity$9(RestHighLevelClient.java:1564)
at org.elasticsearch.client.RestHighLevelClient.internalPerformRequest(RestHighLevelClient.java:1628)
at org.elasticsearch.client.RestHighLevelClient.performRequest(RestHighLevelClient.java:1596)
at org.elasticsearch.client.RestHighLevelClient.performRequestAndParseEntity(RestHighLevelClient.java:1563)
at org.elasticsearch.client.IndicesClient.getMapping(IndicesClient.java:282)
Caused by: java.lang.invoke.LambdaConversionException: Invalid receiver type interface org.apache.http.Header; not a subtype of implementation type interface org.apache.http.NameValuePair
at java.base/java.lang.invoke.AbstractValidatingLambdaMetafactory.validateMetafactoryArgs(AbstractValidatingLambdaMetafactory.java:254)
at java.base/java.lang.invoke.LambdaMetafactory.metafactory(LambdaMetafactory.java:327)
at java.base/java.lang.invoke.BootstrapMethodInvoker.invoke(BootstrapMethodInvoker.java:127)
```
When looking for similar events containing the phrase `lambda$performRequestAndParseEntity$9(RestHighLevelClient.java`, users need a field that supports searching in the middle of a string. Keyword would perform poorly, and text would require rethinking the query to match the analyzer and tokenization applied at index time.
#### Command-line execution
The arguments, order of those arguments, and values passed can be arbitrary in a command-line execution. Multiple wildcards patterns may be needed in a single query if searching across multiple arguments, retaining their ordering, or the argument-value pairing is key to the search criteria. If arguments/values are the only criteria regardless of ordering or pairing, using a structured field such as `process.args` would be preferred. Wildcard searching such an unstructured field indexed as keyword, like `process.command_line`, can cause performance challenges.
Example:
```
process.command_line:*\/f foo* AND process.command_line:*\/b bar*
```
Additional cases for wildcard searching against command-line executions:
* Multiple spaces in the command line execution
* Isolating specific substrings where ordering matters
* command obfuscation
## Source data
### Categories
* Windows events
* Sysmon events
* Powershell events
* Web proxies
* Firewalls
* DNS servers
* Endpoint agents
* Application stack traces
### Real-world examples
Each example in this section contains a partial index mapping, a partial event, and one wildcard search query. Each query example uses a leading wildcard on expected high-cardinality fields where `wildcard` is expected to perform better than `keyword`.
**Windows Powershell logging event:**
```
### Mapping (partial)
...
"process" : {
"properties" : {
"command_line" : {
"type" : "wildcard",
"fields" : {
"text" : {
"type" : "text",
"norms" : false
}
}
}
}
}
...
### Event (partial)
"process": {
"pid": 3540,
...
"command_line": "C:\\Windows\\System32\\svchost.exe -k netsvcs -p -s NetSetupSvc"
}
### Query
GET winlogbeat-*/_search
{
"_source": false,
"query": {
"wildcard": {
"process.command_line": {
"value": "*-k netsvcs -p*"
}
}
}
}
```
**Wildcard query against original URL from a squid web proxy event:**
```
### Mapping (partial)
...
"url" : {
"original" : {
"type" : "wildcard",
"fields" : {
"text" : {
"type" : "text",
"norms" : false
}
}
}
...
### Event (partial)
...
"url": {
"original": "http://example.com/cart.do?action=view&itemId=HolyGouda",
"domain": "example.com"
}
...
### Query
GET filebeat-*/_search
{
"_source": false,
"query": {
"wildcard": {
"url.original": {
"value": "*action=view*Gouda"
}
}
}
}
```
## Scope of impact
`keyword` and `wildcard` are both members of the keyword type family but use different underlying data structures. Wildcard uses two data structures to accelerate wildcard and regexp searching:
1. n-gram index of all three character sequences in the string values
2. binary doc value store of the original values
Wildcard fields require more disk space for the additional n-gram index. This disk cost is only recovered if the full doc values are also stored compress better than the compression of the keyword fields for the doc values. Keyword values are compressed based on common-prefixes in the values, but wildcard values use LZ4 based on blocks of 32 values. These two compression approaches vary depending on size, duplicate values, the cardinality of the data, and so on.
### Storage and Indexing Costs
When assembling the initial list of candidate fields to migrate to `wildcard`, we split focus between query performance improvements and removing security blind spots. However, we overlooked the storage and indexing costs when switching fields to be indexed as `wildcard`.
ECS fields will be re-evaluated now in terms of storage and indexing using the following criteria:
* Underestimating cardinality of particular fields. For example, how many unique fields are expected for a given field? Thousands? Hundreds of Thousands? Millions?
* Disk costs for mostly identical values. Which fields are more likely to have values sharing common prefixes and better compression as `keyword`?
### Query Performance
Keyword vs. wildcard query characteristics:
* `keyword` will perform queries faster for a prefix query (`foo*`) on a low-cardinality field (< hundreds of thousands of unique values) than `wildcard.`
* `wildcard` will perform much faster than `keyword` for leading wildcard or regexp queries but only on a high-cardinality field (> millions of unique values).
* `wildcard` fields should avoid being used extensively for sorting and aggregation features
### Ingestion
Any component producing data (Agent, Beats, Logstash, third-party developed, etc.) will need to adopt the mappings in their index templates.
### Usage mechanisms
The `wildcard` type is a member of the keyword family[3]. Grouping field types by family eliminates backward compatibility issues when replacing an older field type with a new, more specialized type on time-based indices (e.g. `keyword` replaced with `wildcard`). The `wildcard` data type will return `keyword` in the field caps API response, and this change will enable both types to behave identically at query time. This feature eliminates concerns arising from Kibana's field compatibility checks in index patterns.
### ECS project
ECS will remain an Apache 2.0 licensed open-source project. However, there will be features available under the Elastic license that will benefit the user experience with the Elastic stack and solutions that have a place in the ECS specification.
## Concerns
### Wildcard and case-insensitivity
Some fields require flexibility in how users search. For example, their content is messy (such as user-agent values) or popular for threat hunters (process command-lines or a PowerShell script). The `wildcard` field provides improved performance of leading `wildcard` and `regex` term-level queries.
#### Resolution
The `case_insensitivity` query parameter was added in Elasticsearch 7.10. Both `keyword` and `wildcard` types are supported, and each type's noted [performance characteristics](#comparison-with-keyword) will be consistent.
### Performance differences
Performance and storage characteristics between `wildcard` and `keyword` will be different[4]. This difference will vary based deployment size and/or the amount of field data duplication. Fields that were previously indexed as `keyword` will switch to `wildcard`. With these fields now indexed as `wildcard`, users will query fields that are indexed as keyword in some indices and as wildcard in others. Any possible indexing or querying differences need to be understood and captured.
Indexing and query performance characteristics of both types were explored. The observations were [noted](#comparison-with-keyword) earlier in this proposal. However, after additional benchmarking, the increases in storage costs and decreasing in index performance were found to be significant enough that we need to revisit our approach.
#### Resolution
The following categories were initially candidates for `wildcard`, but after reviewing the benchmarking data, the fields will not typically have high enough cardinality to make them ideal candidates for `wildcard`.
##### File paths and names
File path values are likely to compress well as `keyword` since `keyword` fields have common-prefix-based compression (`wildcard` values are blocks of 32 values compressed into a single LZ4 blob). In addition to worsened doc values compression, the number of `postings` also increases significantly due to n-grams.
##### Host and Organization Naming
Often, hostname values are duplicated from event to event. An index will usually have thousands of different hosts and is unlikely to see millions of unique hostname values.
Depending on an organization's host naming convention, there's also some possibility of common prefixing (hosts named `USNHCDBRD-D001` and `USNHCW2K8-P001` both share the prefix `USNHC`).
Organization names such as `as.organization.name` and `organization.name` might be better suited to `text.`
##### User Identifiers
User identifiers, like usernames or email addresses, are also likely duplicated across events. Common prefixing is also a potential consideration.
##### Specialized Text Analyzers
For certain field and their values, the use of specialized text analysis could be an alternative to using the `wildcard` data type. For example, adopting the [path hierarchy tokenizer](https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-pathhierarchy-tokenizer.html) for file paths.
### Wildcard field value character limits
ECS applies the `ignore_above` setting to keyword fields to prevent strings longer than 1024 characters from being indexed or stored. Users may raise the setting of `ignore_above`, but Lucene implements a term byte-length limit of 32766, which cannot be adjusted. Wildcard supports an unlimited max character size for a field value. The `wildcard` field type will still have the `ignore_above` option available, and a reasonable limit may need applying to mitigate unexpected side-effects.
#### Resolution
This ability to ingest very long values is considered an advantage of `wildcard` compared to `keyword`. Therefore, the `wildcard` fields will not have an `ignore_above` option defined initially.
## People
The following are the people that consulted on the contents of this RFC.
* @ebeahan | author, sponsor
* @webmat | editorial feedback
* @markharwood | subject matter expert
* @rw-access | editorial feedback
## Footnotes
* [0] Wildcard queries on `text` fields are limited to matching individual tokens rather than the original value of the field.
* [1] Keyword fields are not tokenized like `text` fields, so patterns can match multiple words. However they suffer from slow performance with wildcard searching (especially with leading wildcards).
* [2] https://www.elastic.co/blog/find-strings-within-strings-faster-with-the-new-elasticsearch-wildcard-field
* [3] https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-term-query.html#term-field-params
* [4] https://github.com/elastic/elasticsearch/pull/58483
## References
* [Introductory blog post for the wildcard type](https://www.elastic.co/blog/find-strings-within-strings-faster-with-the-new-elasticsearch-wildcard-field)
* [Wildcard field type in the Elasticsearch docs](elastic.co/guide/en/elasticsearch/reference/current/keyword.html#wildcard-field-type)
* https://github.com/elastic/ecs/issues/570
* https://github.com/elastic/mechagodzilla/issues/2
* https://github.com/elastic/ecs/issues/105
### RFC Pull Requests
Due to performance concerns brought up during implementation, the wildcard changes were [rolled back](https://github.com/elastic/ecs/pull/1237) to iterate on this proposal with a focus on performance implications. The original round of PRs are listed under `First Phase`, and the PRs following the rollback are grouped under `Second Phase`.
#### First Phase
* Stage 0 (strawperson): https://github.com/elastic/ecs/pull/890
* Stage 1 (proposal): https://github.com/elastic/ecs/pull/904
* Stage 2 (draft): https://github.com/elastic/ecs/pull/970
* Stage 3 (candidate): https://github.com/elastic/ecs/pull/1015
#### Second Phase
* Stage 1 (draft):
* Rollback: https://github.com/elastic/ecs/pull/1237
* Stage 2 (candidate): https://github.com/elastic/ecs/pull/1247
* Stage 3 (finished): https://github.com/elastic/ecs/pull/1530
### Use Cases
The following sections detail use cases which could benefit using the `wildcard` type.
#### Stack traces
Program stack traces tend to be well-structured but with long text and varied contents. There are too many subtleties and application-specific patterns to map all of them accurately with ECS' field definitions. Better performing wildcard searches can help users formulate their queries easier and with a less significant performance hit.
Looking at the following example of a stack trace:
```java
bootstrap method initialization exception
at java.base/java.lang.invoke.BootstrapMethodInvoker.invoke(BootstrapMethodInvoker.java:194)
at java.base/java.lang.invoke.CallSite.makeSite(CallSite.java:315)
at java.base/java.lang.invoke.MethodHandleNatives.linkCallSiteImpl(MethodHandleNatives.java:259)
at java.base/java.lang.invoke.MethodHandleNatives.linkCallSite(MethodHandleNatives.java:249)
at org.elasticsearch.client.RestHighLevelClient.parseEntity(RestHighLevelClient.java:1883)
at org.elasticsearch.client.RestHighLevelClient.lambda$performRequestAndParseEntity$9(RestHighLevelClient.java:1564)
at org.elasticsearch.client.RestHighLevelClient.internalPerformRequest(RestHighLevelClient.java:1628)
at org.elasticsearch.client.RestHighLevelClient.performRequest(RestHighLevelClient.java:1596)
at org.elasticsearch.client.RestHighLevelClient.performRequestAndParseEntity(RestHighLevelClient.java:1563)
at org.elasticsearch.client.IndicesClient.getMapping(IndicesClient.java:282)
Caused by: java.lang.invoke.LambdaConversionException: Invalid receiver type interface org.apache.http.Header; not a subtype of implementation type interface org.apache.http.NameValuePair
at java.base/java.lang.invoke.AbstractValidatingLambdaMetafactory.validateMetafactoryArgs(AbstractValidatingLambdaMetafactory.java:254)
at java.base/java.lang.invoke.LambdaMetafactory.metafactory(LambdaMetafactory.java:327)
at java.base/java.lang.invoke.BootstrapMethodInvoker.invoke(BootstrapMethodInvoker.java:127)
```
When looking for similar events containing the phrase `lambda$performRequestAndParseEntity$9(RestHighLevelClient.java`, users need a field that supports searching in the middle of a string. Keyword would perform poorly, and text would require rethinking the query to match the analyzer and tokenization applied at index time.
#### Command-line execution
The arguments, order of those arguments, and values passed can be arbitrary in a command-line execution. Multiple wildcards patterns may be needed in a single query if searching across multiple arguments, retaining their ordering, or the argument-value pairing is key to the search criteria. If arguments/values are the only criteria regardless of ordering or pairing, using a structured field such as `process.args` would be preferred. Wildcard searching such an unstructured field indexed as keyword, like `process.command_line`, can cause performance challenges.
Example:
```
process.command_line:*\/f foo* AND process.command_line:*\/b bar*
```
Additional cases for wildcard searching against command-line executions:
* Multiple spaces in the command line execution
* Isolating specific substrings where ordering matters
* command obfuscation
## Source data
### Categories
* Windows events
* Sysmon events
* Powershell events
* Web proxies
* Firewalls
* DNS servers
* Endpoint agents
* Application stack traces
### Real-world examples
Each example in this section contains a partial index mapping, a partial event, and one wildcard search query. Each query example uses a leading wildcard on expected high-cardinality fields where `wildcard` is expected to perform better than `keyword`.
**Windows Powershell logging event:**
```
### Mapping (partial)
...
"process" : {
"properties" : {
"command_line" : {
"type" : "wildcard",
"fields" : {
"text" : {
"type" : "text",
"norms" : false
}
}
}
}
}
...
### Event (partial)
"process": {
"pid": 3540,
...
"command_line": "C:\\Windows\\System32\\svchost.exe -k netsvcs -p -s NetSetupSvc"
}
### Query
GET winlogbeat-*/_search
{
"_source": false,
"query": {
"wildcard": {
"process.command_line": {
"value": "*-k netsvcs -p*"
}
}
}
}
```
**Wildcard query against original URL from a squid web proxy event:**
```
### Mapping (partial)
...
"url" : {
"original" : {
"type" : "wildcard",
"fields" : {
"text" : {
"type" : "text",
"norms" : false
}
}
}
...
### Event (partial)
...
"url": {
"original": "http://example.com/cart.do?action=view&itemId=HolyGouda",
"domain": "example.com"
}
...
### Query
GET filebeat-*/_search
{
"_source": false,
"query": {
"wildcard": {
"url.original": {
"value": "*action=view*Gouda"
}
}
}
}
```
## Scope of impact
`keyword` and `wildcard` are both members of the keyword type family but use different underlying data structures. Wildcard uses two data structures to accelerate wildcard and regexp searching:
1. n-gram index of all three character sequences in the string values
2. binary doc value store of the original values
Wildcard fields require more disk space for the additional n-gram index. This disk cost is only recovered if the full doc values are also stored compress better than the compression of the keyword fields for the doc values. Keyword values are compressed based on common-prefixes in the values, but wildcard values use LZ4 based on blocks of 32 values. These two compression approaches vary depending on size, duplicate values, the cardinality of the data, and so on.
### Storage and Indexing Costs
When assembling the initial list of candidate fields to migrate to `wildcard`, we split focus between query performance improvements and removing security blind spots. However, we overlooked the storage and indexing costs when switching fields to be indexed as `wildcard`.
ECS fields will be re-evaluated now in terms of storage and indexing using the following criteria:
* Underestimating cardinality of particular fields. For example, how many unique fields are expected for a given field? Thousands? Hundreds of Thousands? Millions?
* Disk costs for mostly identical values. Which fields are more likely to have values sharing common prefixes and better compression as `keyword`?
### Query Performance
Keyword vs. wildcard query characteristics:
* `keyword` will perform queries faster for a prefix query (`foo*`) on a low-cardinality field (< hundreds of thousands of unique values) than `wildcard.`
* `wildcard` will perform much faster than `keyword` for leading wildcard or regexp queries but only on a high-cardinality field (> millions of unique values).
* `wildcard` fields should avoid being used extensively for sorting and aggregation features
### Ingestion
Any component producing data (Agent, Beats, Logstash, third-party developed, etc.) will need to adopt the mappings in their index templates.
### Usage mechanisms
The `wildcard` type is a member of the keyword family[3]. Grouping field types by family eliminates backward compatibility issues when replacing an older field type with a new, more specialized type on time-based indices (e.g. `keyword` replaced with `wildcard`). The `wildcard` data type will return `keyword` in the field caps API response, and this change will enable both types to behave identically at query time. This feature eliminates concerns arising from Kibana's field compatibility checks in index patterns.
### ECS project
ECS will remain an Apache 2.0 licensed open-source project. However, there will be features available under the Elastic license that will benefit the user experience with the Elastic stack and solutions that have a place in the ECS specification.
## Concerns
### Wildcard and case-insensitivity
Some fields require flexibility in how users search. For example, their content is messy (such as user-agent values) or popular for threat hunters (process command-lines or a PowerShell script). The `wildcard` field provides improved performance of leading `wildcard` and `regex` term-level queries.
#### Resolution
The `case_insensitivity` query parameter was added in Elasticsearch 7.10. Both `keyword` and `wildcard` types are supported, and each type's noted [performance characteristics](#comparison-with-keyword) will be consistent.
### Performance differences
Performance and storage characteristics between `wildcard` and `keyword` will be different[4]. This difference will vary based deployment size and/or the amount of field data duplication. Fields that were previously indexed as `keyword` will switch to `wildcard`. With these fields now indexed as `wildcard`, users will query fields that are indexed as keyword in some indices and as wildcard in others. Any possible indexing or querying differences need to be understood and captured.
Indexing and query performance characteristics of both types were explored. The observations were [noted](#comparison-with-keyword) earlier in this proposal. However, after additional benchmarking, the increases in storage costs and decreasing in index performance were found to be significant enough that we need to revisit our approach.
#### Resolution
The following categories were initially candidates for `wildcard`, but after reviewing the benchmarking data, the fields will not typically have high enough cardinality to make them ideal candidates for `wildcard`.
##### File paths and names
File path values are likely to compress well as `keyword` since `keyword` fields have common-prefix-based compression (`wildcard` values are blocks of 32 values compressed into a single LZ4 blob). In addition to worsened doc values compression, the number of `postings` also increases significantly due to n-grams.
##### Host and Organization Naming
Often, hostname values are duplicated from event to event. An index will usually have thousands of different hosts and is unlikely to see millions of unique hostname values.
Depending on an organization's host naming convention, there's also some possibility of common prefixing (hosts named `USNHCDBRD-D001` and `USNHCW2K8-P001` both share the prefix `USNHC`).
Organization names such as `as.organization.name` and `organization.name` might be better suited to `text.`
##### User Identifiers
User identifiers, like usernames or email addresses, are also likely duplicated across events. Common prefixing is also a potential consideration.
##### Specialized Text Analyzers
For certain field and their values, the use of specialized text analysis could be an alternative to using the `wildcard` data type. For example, adopting the [path hierarchy tokenizer](https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-pathhierarchy-tokenizer.html) for file paths.
### Wildcard field value character limits
ECS applies the `ignore_above` setting to keyword fields to prevent strings longer than 1024 characters from being indexed or stored. Users may raise the setting of `ignore_above`, but Lucene implements a term byte-length limit of 32766, which cannot be adjusted. Wildcard supports an unlimited max character size for a field value. The `wildcard` field type will still have the `ignore_above` option available, and a reasonable limit may need applying to mitigate unexpected side-effects.
#### Resolution
This ability to ingest very long values is considered an advantage of `wildcard` compared to `keyword`. Therefore, the `wildcard` fields will not have an `ignore_above` option defined initially.
## People
The following are the people that consulted on the contents of this RFC.
* @ebeahan | author, sponsor
* @webmat | editorial feedback
* @markharwood | subject matter expert
* @rw-access | editorial feedback
## Footnotes
* [0] Wildcard queries on `text` fields are limited to matching individual tokens rather than the original value of the field.
* [1] Keyword fields are not tokenized like `text` fields, so patterns can match multiple words. However they suffer from slow performance with wildcard searching (especially with leading wildcards).
* [2] https://www.elastic.co/blog/find-strings-within-strings-faster-with-the-new-elasticsearch-wildcard-field
* [3] https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-term-query.html#term-field-params
* [4] https://github.com/elastic/elasticsearch/pull/58483
## References
* [Introductory blog post for the wildcard type](https://www.elastic.co/blog/find-strings-within-strings-faster-with-the-new-elasticsearch-wildcard-field)
* [Wildcard field type in the Elasticsearch docs](elastic.co/guide/en/elasticsearch/reference/current/keyword.html#wildcard-field-type)
* https://github.com/elastic/ecs/issues/570
* https://github.com/elastic/mechagodzilla/issues/2
* https://github.com/elastic/ecs/issues/105
### RFC Pull Requests
Due to performance concerns brought up during implementation, the wildcard changes were [rolled back](https://github.com/elastic/ecs/pull/1237) to iterate on this proposal with a focus on performance implications. The original round of PRs are listed under `First Phase`, and the PRs following the rollback are grouped under `Second Phase`.
#### First Phase
* Stage 0 (strawperson): https://github.com/elastic/ecs/pull/890
* Stage 1 (proposal): https://github.com/elastic/ecs/pull/904
* Stage 2 (draft): https://github.com/elastic/ecs/pull/970
* Stage 3 (candidate): https://github.com/elastic/ecs/pull/1015
#### Second Phase
* Stage 1 (draft):
* Rollback: https://github.com/elastic/ecs/pull/1237
* Stage 2 (candidate): https://github.com/elastic/ecs/pull/1247
* Stage 3 (finished): https://github.com/elastic/ecs/pull/1530