hotsax
An implementation of the HOTSAX discord discovery algorithm.
{{readme}}
## Evaluation
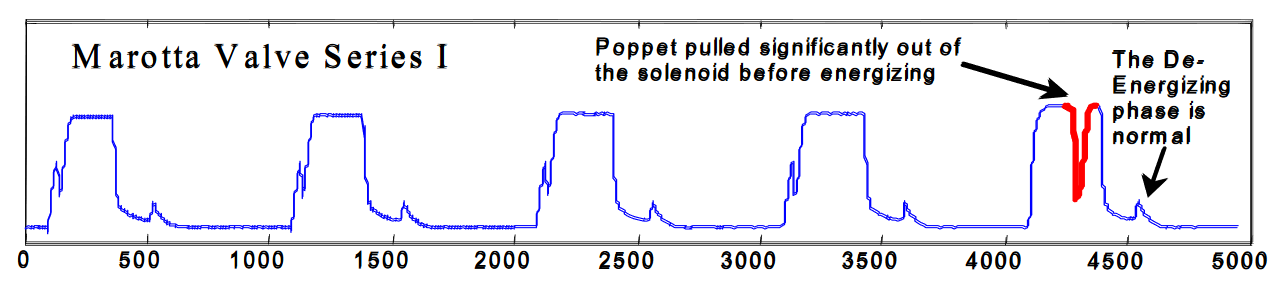
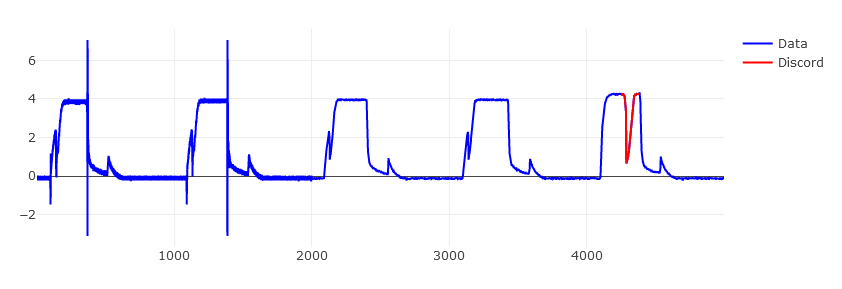
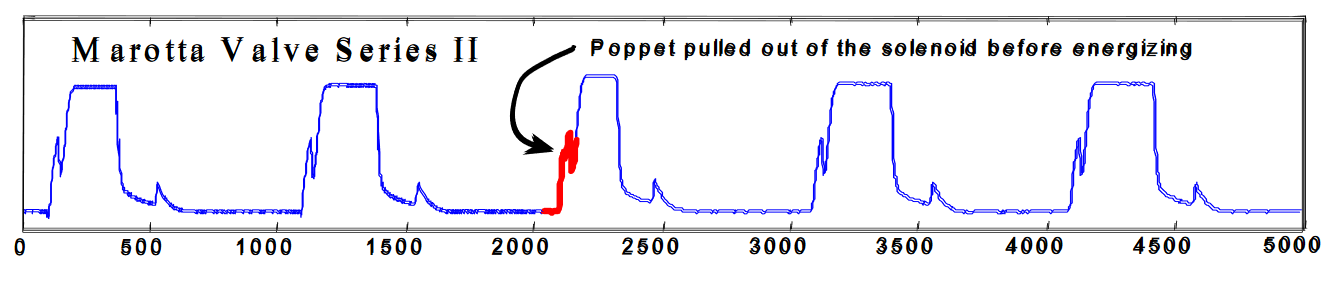
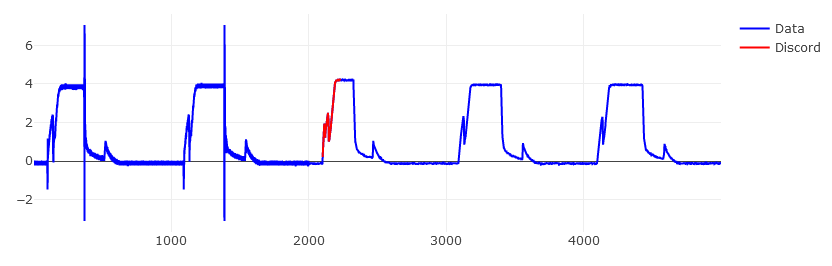
To show the accuracy of the implementation, the algorithm was run on the same
dataset as used in the paper itself. Specifically, data from Figure 6 and Figure 7
(as can be retrieved [here](https://www.cs.ucr.edu/~eamonn/discords/), or from the `data/`
directory of this repository as `TEK16.CSV` and `TEK17.CSV` respectively.
The algorithm was ran with a word size of 3, an alphabet size of 3, and a discord size of 128.
Below show the results of this algorithm, compared with the figures shown in the paper.