[](https://travis-ci.org/urschrei/lonlat_bng) [](https://ci.appveyor.com/project/urschrei/lonlat-bng) [](https://coveralls.io/github/urschrei/lonlat_bng?branch=master) [](https://crates.io/crates/lonlat_bng) [](license.txt) [](https://zenodo.org/badge/latestdoi/3657/urschrei/lonlat_bng)
# Introduction
 A Rust library with FFI bindings for fast conversion between WGS84 longitude and latitude and British National Grid ([epsg:27700](http://spatialreference.org/ref/epsg/osgb-1936-british-national-grid/)) coordinates, using a Rust binary. Conversions use a standard 7-element Helmert transform with the addition of OSTN02 corrections for [accuracy](#accuracy).
# Motivation
Python (etc.) is relatively slow; this type of conversion is usually carried out in bulk, so an order-of-magnitude improvement using FFI saves both time and energy.
# Accuracy
Conversions which solely use Helmert transforms are accurate to within around 5 metres, and are **not suitable** for calculations or conversions used in e.g. surveying. Thus, we use the OSTN02 transform, which adjusts for local variation within the Terrestrial Reference Frame by incorporating OSTN02 data. [See here](http://www.ordnancesurvey.co.uk/business-and-government/help-and-support/navigation-technology/os-net/surveying.html) for more information.
The OSTN02-enabled functions are:
- convert_bng_threaded (an alias for convert_osgb36_threaded)
- convert_bng_threaded_vec ← FFI version of the above
- convert_lonlat_threaded (an alias for convert_osgb36_to_ll)
- convert_lonlat_threaded_vec ← FFI version of the above
- convert_osgb36
- convert_etrs89_to_osgb36
- convert_to_osgb36_threaded ← FFI
- convert_to_osgb36_threaded_vec
- convert_etrs89_to_osgb36_threaded ← FFI
- convert_etrs89_to_osgb36_threaded_vec
- convert_osgb36_to_ll_threaded ← FFI
- convert_osgb36_to_ll_threaded_vec
- convert_osgb36_to_etrs89_threaded ← FFI
- convert_osgb36_to_etrs89_threaded_vec
[]( "OSTN02")
# Library Use
## As a Rust Library
Add the following to your `Cargo.toml` (the latest version is displayed on the fourth badge at the top of this screen)
lonlat_bng = "x.x.x"
Full library documentation is available [here](http://urschrei.github.io/lonlat_bng/)
**Note that `lon`, `lat` coordinates outside the [UK bounding box](http://spatialreference.org/ref/epsg/27700/) will be transformed to `(NAN, NAN)`, which cannot be mapped.**
The functions exposed by the library can be found [here](http://urschrei.github.io/lonlat_bng/lonlat_bng/index.html#functions)
## As an FFI Library
The FFI C-compatible functions exposed by the library are:
`convert_to_bng_threaded(Array, Array) -> Array`
`convert_to_lonlat_threaded(Array, Array) -> Array`
`convert_to_osgb36_threaded(Array, Array) -> Array`
`convert_to_etrs89_threaded(Array, Array) -> Array)`
`convert_osgb36_to_ll_threaded(Array, Array) -> Array`
`convert_etrs89_to_ll_threaded(Array, Array) -> Array`
`convert_etrs89_to_osgb36_threaded(Array, Array) -> Array`
`convert_osgb36_to_etrs89_threaded(Array, Array) -> Array`
`convert_epsg3857_to_wgs84_threaded(Array, Array) -> Array`
### FFI and Memory Management
If your library, module, or script uses the FFI functions, it **must** implement `drop_float_array`. **Failing to do so may result in memory leaks**. It has the following signature: `drop_float_array(ar1: Array, ar2: Array)`
The Array structs you pass to `drop_float_array` must be those you receive from the FFI function. For examples, see the `Array` struct and tests in [ffi.rs](src/ffi.rs), and the `_FFIArray` class in [convertbng](https://github.com/urschrei/convertbng/blob/master/convertbng/util.py).
### Building the Shared Library
Running `cargo build --release` will build an artefact called `liblonlat_bng.dylib` on OSX, and `liblonlat_bng.a` on `*nix` systems. Note that you'll have to generate `liblonlat_bng.so` for `*nix` hosts using the following steps:
- `ar -x target/release/liblonlat_bng.a`
- `gcc -shared *.o -o target/release/liblonlat_bng.so -lrt`
## As a Python Package
`convert_bng` is [available](https://pypi.python.org/pypi/convertbng/) from PyPI for OSX and *nix:
`pip install convertbng`
More information is available in its [repository](https://github.com/urschrei/rust_bng)
# Benchmark
A CProfile [benchmark](remote_bench.py) was run, comparing 50 runs of converting 1m random lon, lat pairs in NumPy arrays.
## Methodology
- 4 [Amazon EC2 C4](http://docs.aws.amazon.com/AWSEC2/latest/UserGuide/c4-instances.html) (compute-optimised) systems were tested
- The system was first calibrated by taking the mean of five calibration runs of 100,000 repeats
- A benchmark program was then run for each of the three configurations. See the [benches](benches) directory for details
- The five slowest function calls for each benchmark were then displayed.
## Results
| EC2 Instance Type | Processors (vCPU) | Rust Ctypes (s) | Rust Cython (s) | Pyproj (s) | % change, Ctypes vs Pyproj | % change, Pyproj vs Cython |
|:---------------------|:-----------------:|:---------------:|:---------------:|:----------:|:--------------------------:|---------------------------:|
| c4.xlarge | 4 | 42.075 | 27.964 | 18.73 | 124.64% | -33.02% |
| c4.2xlarge | 8 | 28.743 | 14.094 | 19.055 | 50.84% | 35.20% |
| c4.4xlarge | 16 | 22.108 | 7.554 | 18.797 | 17.61% | 148.84% |
| c4.8xlarge | 36 | 18.288 | 4.42 | 18.285 | 0.02% | 313.69% |
## Conclusion
Using multithreading gives excellent performance; Pyproj – which is a compiled [Cython](http://cython.org) binary – is less than 20% faster than Rust + Ctypes on a 16-CPU system, and gives identical performance on 36 CPUs.
A compiled Cython binary + Rust is faster than Pyproj on an 8-CPU system, and outperforms Pyproj by greater margins as the number of CPUs increase: at 36 CPUs, it is over 300% faster.
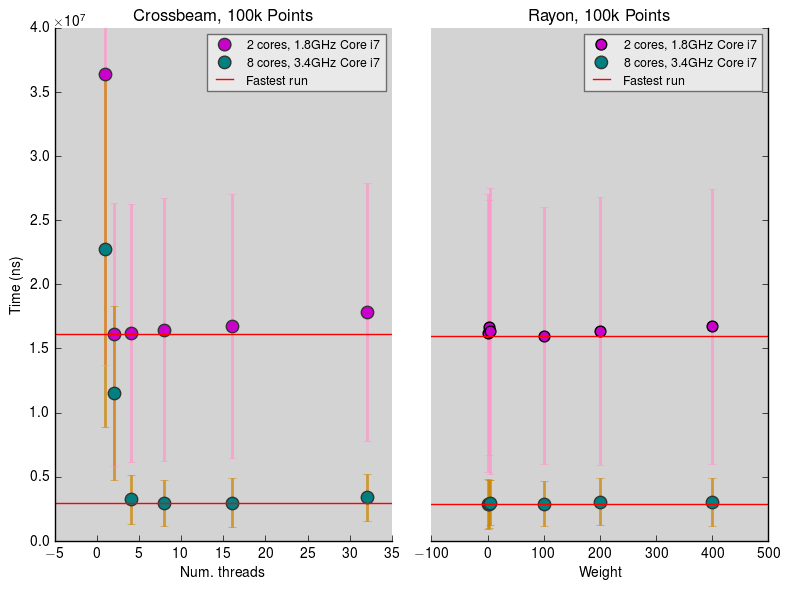
# Comparing Crossbeam and Rayon
Comparing how varying threads and weights affects overall speed, using [`cargo bench`](benches/benchmarks.rs)
On both 2- and 8-core i7 machines, running `convert_bng_threaded_vec` using one thread per core gives optimum performance, whereas Rayon does a good job at choosing its own optimum weight.
A Rust library with FFI bindings for fast conversion between WGS84 longitude and latitude and British National Grid ([epsg:27700](http://spatialreference.org/ref/epsg/osgb-1936-british-national-grid/)) coordinates, using a Rust binary. Conversions use a standard 7-element Helmert transform with the addition of OSTN02 corrections for [accuracy](#accuracy).
# Motivation
Python (etc.) is relatively slow; this type of conversion is usually carried out in bulk, so an order-of-magnitude improvement using FFI saves both time and energy.
# Accuracy
Conversions which solely use Helmert transforms are accurate to within around 5 metres, and are **not suitable** for calculations or conversions used in e.g. surveying. Thus, we use the OSTN02 transform, which adjusts for local variation within the Terrestrial Reference Frame by incorporating OSTN02 data. [See here](http://www.ordnancesurvey.co.uk/business-and-government/help-and-support/navigation-technology/os-net/surveying.html) for more information.
The OSTN02-enabled functions are:
- convert_bng_threaded (an alias for convert_osgb36_threaded)
- convert_bng_threaded_vec ← FFI version of the above
- convert_lonlat_threaded (an alias for convert_osgb36_to_ll)
- convert_lonlat_threaded_vec ← FFI version of the above
- convert_osgb36
- convert_etrs89_to_osgb36
- convert_to_osgb36_threaded ← FFI
- convert_to_osgb36_threaded_vec
- convert_etrs89_to_osgb36_threaded ← FFI
- convert_etrs89_to_osgb36_threaded_vec
- convert_osgb36_to_ll_threaded ← FFI
- convert_osgb36_to_ll_threaded_vec
- convert_osgb36_to_etrs89_threaded ← FFI
- convert_osgb36_to_etrs89_threaded_vec
[]( "OSTN02")
# Library Use
## As a Rust Library
Add the following to your `Cargo.toml` (the latest version is displayed on the fourth badge at the top of this screen)
lonlat_bng = "x.x.x"
Full library documentation is available [here](http://urschrei.github.io/lonlat_bng/)
**Note that `lon`, `lat` coordinates outside the [UK bounding box](http://spatialreference.org/ref/epsg/27700/) will be transformed to `(NAN, NAN)`, which cannot be mapped.**
The functions exposed by the library can be found [here](http://urschrei.github.io/lonlat_bng/lonlat_bng/index.html#functions)
## As an FFI Library
The FFI C-compatible functions exposed by the library are:
`convert_to_bng_threaded(Array, Array) -> Array`
`convert_to_lonlat_threaded(Array, Array) -> Array`
`convert_to_osgb36_threaded(Array, Array) -> Array`
`convert_to_etrs89_threaded(Array, Array) -> Array)`
`convert_osgb36_to_ll_threaded(Array, Array) -> Array`
`convert_etrs89_to_ll_threaded(Array, Array) -> Array`
`convert_etrs89_to_osgb36_threaded(Array, Array) -> Array`
`convert_osgb36_to_etrs89_threaded(Array, Array) -> Array`
`convert_epsg3857_to_wgs84_threaded(Array, Array) -> Array`
### FFI and Memory Management
If your library, module, or script uses the FFI functions, it **must** implement `drop_float_array`. **Failing to do so may result in memory leaks**. It has the following signature: `drop_float_array(ar1: Array, ar2: Array)`
The Array structs you pass to `drop_float_array` must be those you receive from the FFI function. For examples, see the `Array` struct and tests in [ffi.rs](src/ffi.rs), and the `_FFIArray` class in [convertbng](https://github.com/urschrei/convertbng/blob/master/convertbng/util.py).
### Building the Shared Library
Running `cargo build --release` will build an artefact called `liblonlat_bng.dylib` on OSX, and `liblonlat_bng.a` on `*nix` systems. Note that you'll have to generate `liblonlat_bng.so` for `*nix` hosts using the following steps:
- `ar -x target/release/liblonlat_bng.a`
- `gcc -shared *.o -o target/release/liblonlat_bng.so -lrt`
## As a Python Package
`convert_bng` is [available](https://pypi.python.org/pypi/convertbng/) from PyPI for OSX and *nix:
`pip install convertbng`
More information is available in its [repository](https://github.com/urschrei/rust_bng)
# Benchmark
A CProfile [benchmark](remote_bench.py) was run, comparing 50 runs of converting 1m random lon, lat pairs in NumPy arrays.
## Methodology
- 4 [Amazon EC2 C4](http://docs.aws.amazon.com/AWSEC2/latest/UserGuide/c4-instances.html) (compute-optimised) systems were tested
- The system was first calibrated by taking the mean of five calibration runs of 100,000 repeats
- A benchmark program was then run for each of the three configurations. See the [benches](benches) directory for details
- The five slowest function calls for each benchmark were then displayed.
## Results
| EC2 Instance Type | Processors (vCPU) | Rust Ctypes (s) | Rust Cython (s) | Pyproj (s) | % change, Ctypes vs Pyproj | % change, Pyproj vs Cython |
|:---------------------|:-----------------:|:---------------:|:---------------:|:----------:|:--------------------------:|---------------------------:|
| c4.xlarge | 4 | 42.075 | 27.964 | 18.73 | 124.64% | -33.02% |
| c4.2xlarge | 8 | 28.743 | 14.094 | 19.055 | 50.84% | 35.20% |
| c4.4xlarge | 16 | 22.108 | 7.554 | 18.797 | 17.61% | 148.84% |
| c4.8xlarge | 36 | 18.288 | 4.42 | 18.285 | 0.02% | 313.69% |
## Conclusion
Using multithreading gives excellent performance; Pyproj – which is a compiled [Cython](http://cython.org) binary – is less than 20% faster than Rust + Ctypes on a 16-CPU system, and gives identical performance on 36 CPUs.
A compiled Cython binary + Rust is faster than Pyproj on an 8-CPU system, and outperforms Pyproj by greater margins as the number of CPUs increase: at 36 CPUs, it is over 300% faster.
# Comparing Crossbeam and Rayon
Comparing how varying threads and weights affects overall speed, using [`cargo bench`](benches/benchmarks.rs)
On both 2- and 8-core i7 machines, running `convert_bng_threaded_vec` using one thread per core gives optimum performance, whereas Rayon does a good job at choosing its own optimum weight.
 # License
[MIT](license.txt)
This software makes use of OSTN02 data, which is © Crown copyright, Ordnance Survey and the Ministry of Defence (MOD) 2002. All rights reserved. Provided under the BSD 2-clause [license](OSTN02_license.txt).
† Really, pyproj?
[]( "MEDIOCRE")
# License
[MIT](license.txt)
This software makes use of OSTN02 data, which is © Crown copyright, Ordnance Survey and the Ministry of Defence (MOD) 2002. All rights reserved. Provided under the BSD 2-clause [license](OSTN02_license.txt).
† Really, pyproj?
[]( "MEDIOCRE")