# orx-concurrent-bag
[](https://crates.io/crates/orx-concurrent-bag)
[](https://docs.rs/orx-concurrent-bag)
An efficient, convenient and lightweight grow-only concurrent data structure allowing high performance concurrent collection.
* **convenient**: `ConcurrentBag` can safely be shared among threads simply as a shared reference. It is a [`PinnedConcurrentCol`](https://crates.io/crates/orx-pinned-concurrent-col) with a special concurrent state implementation. Underlying [`PinnedVec`](https://crates.io/crates/orx-pinned-vec) and concurrent bag can be converted back and forth to each other.
* **efficient**: `ConcurrentBag` is a lock free structure suitable for concurrent, copy-free and high performance growth. You may see benchmarks and further performance notes for details.
## Examples
Underlying `PinnedVec` guarantees make it straightforward to safely grow with a shared reference which leads to a convenient api as demonstrated below.
```rust
use orx_concurrent_bag::*;
let bag = ConcurrentBag::new();
let (num_threads, num_items_per_thread) = (4, 1_024);
let bag_ref = &bag;
std::thread::scope(|s| {
for i in 0..num_threads {
s.spawn(move || {
for j in 0..num_items_per_thread {
// concurrently collect results simply by calling `push`
bag_ref.push(i * 1000 + j);
}
});
}
});
let mut vec_from_bag = bag.into_inner().to_vec();
vec_from_bag.sort();
let mut expected: Vec<_> = (0..num_threads).flat_map(|i| (0..num_items_per_thread).map(move |j| i * 1000 + j)).collect();
expected.sort();
assert_eq!(vec_from_bag, expected);
```
## Concurrent State and Properties
The concurrent state is modeled simply by an atomic length. Combination of this state and `PinnedConcurrentCol` leads to the following properties:
* Writing to a position of the collection does not block other writes, multiple writes can happen concurrently.
* Each position is written exactly once.
* ⟹ no write & write race condition exists.
* Only one growth can happen at a given time. Growth is copy-free and does not change memory locations of already pushed elements.
* Underlying pinned vector is always valid and can be taken out any time by `into_inner(self)`.
* Reading is only possible after converting the bag into the underlying `PinnedVec`.
* ⟹ no read & write race condition exists.
## Benchmarks
### Performance with `push`
*You may find the details of the benchmarks at [benches/collect_with_push.rs](https://github.com/orxfun/orx-concurrent-bag/blob/main/benches/collect_with_push.rs).*
In the experiment, `rayon`s parallel iterator, and push methods of `AppendOnlyVec`, `boxcar::Vec` and `ConcurrentBag` are used to collect results from multiple threads. Further, different underlying pinned vectors of the `ConcurrentBag` are evaluated.
```rust ignore
// reserve and push one position at a time
for j in 0..num_items_per_thread {
bag.push(i * 1000 + j);
}
```
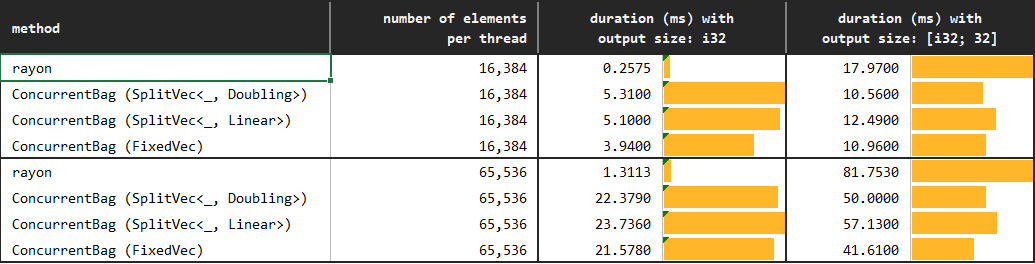 We observe that `ConcurrentBag` allows for a highly efficient concurrent collection of elements:
* The default `Doubling` growth strategy of the concurrent bag, which is the most flexible as it does not require any prior knowledge, already seems to outperform the alternatives. Hence, it can be used in most situations.
* `Linear` growth strategy requires one argument determining the uniform fragment capacity of the underlying `SplitVec`. This strategy might be preferred whenever we would like to be more conservative about allocation. Recall that capacity of `Doubling`, similar to the standard Vec, grows exponentially; while as the name suggests `Linear` grows linearly.
* Finally, `Fixed` growth strategy is the least flexible and requires perfect knowledge about the hard-constrained capacity (will panic if we exceed). Since it does not outperform `Doubling` or `Linear`, we do not necessarily required to use `Fixed` except for the rare cases where we want to allocate exactly the required memory that we know beforehand.
The performance can further be improved by using `extend` method instead of `push`. You may see results in the next subsection and details in the performance notes.
### Performance with `extend`
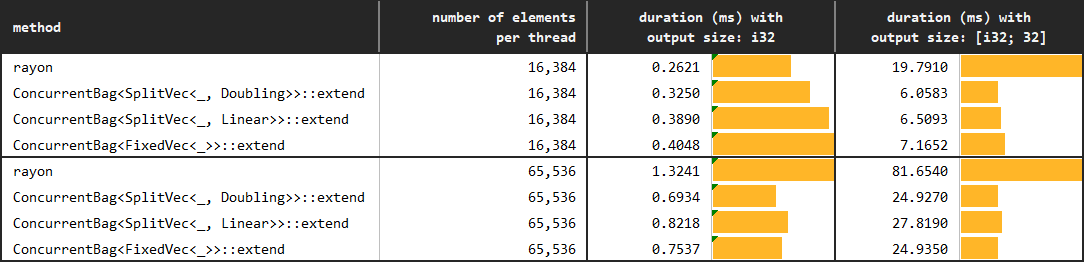
*You may find the details of the benchmarks at [benches/collect_with_extend.rs](https://github.com/orxfun/orx-concurrent-bag/blob/main/benches/collect_with_extend.rs).*
The only difference in this follow up experiment is that we use `extend` rather than `push` with `ConcurrentBag`. The expectation is that this approach will solve the performance degradation due to false sharing in the *small data & little work* situation.
In a perfectly homogeneous scenario, we can evenly share the work to threads as follows.
```rust ignore
// reserve num_items_per_thread positions at a time
// and then push as the iterator yields
let iter = (0..num_items_per_thread).map(|j| i * 100000 + j);
bag.extend(iter);
```
However, we do not need to have perfect homogeneity or perfect information on the number of items to be pushed per thread to get the benefits of `extend`. We can simply `step_by` and extend by `batch_size` elements. A large enough `batch_size` so that batch size elements exceed a cache line would be sufficient to prevent the dramatic performance degradation of false sharing.
```rust ignore
// reserve batch_size positions at each iteration
// and then push as the iterator yields
for j in (0..num_items_per_thread).step_by(batch_size) {
let iter = (j..(j + batch_size)).map(|j| i * 100000 + j);
bag.extend(iter);
}
```
Although concurrent collection via `ConcurrentBag::push` is highly efficient, collection with `ConcurrentBag::extend` certainly needs to be considered whenever possible as it changes the scale. As the graph below demonstrates, collection in batches of only 64 elements while collecting tens of thousands of elements provides orders of magnitudes of improvement.
We observe that `ConcurrentBag` allows for a highly efficient concurrent collection of elements:
* The default `Doubling` growth strategy of the concurrent bag, which is the most flexible as it does not require any prior knowledge, already seems to outperform the alternatives. Hence, it can be used in most situations.
* `Linear` growth strategy requires one argument determining the uniform fragment capacity of the underlying `SplitVec`. This strategy might be preferred whenever we would like to be more conservative about allocation. Recall that capacity of `Doubling`, similar to the standard Vec, grows exponentially; while as the name suggests `Linear` grows linearly.
* Finally, `Fixed` growth strategy is the least flexible and requires perfect knowledge about the hard-constrained capacity (will panic if we exceed). Since it does not outperform `Doubling` or `Linear`, we do not necessarily required to use `Fixed` except for the rare cases where we want to allocate exactly the required memory that we know beforehand.
The performance can further be improved by using `extend` method instead of `push`. You may see results in the next subsection and details in the performance notes.
### Performance with `extend`
*You may find the details of the benchmarks at [benches/collect_with_extend.rs](https://github.com/orxfun/orx-concurrent-bag/blob/main/benches/collect_with_extend.rs).*
The only difference in this follow up experiment is that we use `extend` rather than `push` with `ConcurrentBag`. The expectation is that this approach will solve the performance degradation due to false sharing in the *small data & little work* situation.
In a perfectly homogeneous scenario, we can evenly share the work to threads as follows.
```rust ignore
// reserve num_items_per_thread positions at a time
// and then push as the iterator yields
let iter = (0..num_items_per_thread).map(|j| i * 100000 + j);
bag.extend(iter);
```
However, we do not need to have perfect homogeneity or perfect information on the number of items to be pushed per thread to get the benefits of `extend`. We can simply `step_by` and extend by `batch_size` elements. A large enough `batch_size` so that batch size elements exceed a cache line would be sufficient to prevent the dramatic performance degradation of false sharing.
```rust ignore
// reserve batch_size positions at each iteration
// and then push as the iterator yields
for j in (0..num_items_per_thread).step_by(batch_size) {
let iter = (j..(j + batch_size)).map(|j| i * 100000 + j);
bag.extend(iter);
}
```
Although concurrent collection via `ConcurrentBag::push` is highly efficient, collection with `ConcurrentBag::extend` certainly needs to be considered whenever possible as it changes the scale. As the graph below demonstrates, collection in batches of only 64 elements while collecting tens of thousands of elements provides orders of magnitudes of improvement.
 ## Concurrent Friend Collections
||[`ConcurrentBag`](https://crates.io/crates/orx-concurrent-bag)|[`ConcurrentVec`](https://crates.io/crates/orx-concurrent-vec)|[`ConcurrentOrderedBag`](https://crates.io/crates/orx-concurrent-ordered-bag)|
|---|---|---|---|
| Write | Guarantees that each element is written exactly once via `push` or `extend` methods | Guarantees that each element is written exactly once via `push` or `extend` methods | Different in two ways. First, a position can be written multiple times. Second, an arbitrary element of the bag can be written at any time at any order using `set_value` and `set_values` methods. This provides a great flexibility while moving the safety responsibility to the caller; hence, the set methods are `unsafe`. |
| Read | Mainly, a write-only collection. Concurrent reading of already pushed elements is through `unsafe` `get` and `iter` methods. The caller is required to avoid race conditions. | A write-and-read collection. Already pushed elements can safely be read through `get` and `iter` methods. | Not supported currently. Due to the flexible but unsafe nature of write operations, it is difficult to provide required safety guarantees as a caller. |
| Ordering of Elements | Since write operations are through adding elements to the end of the pinned vector via `push` and `extend`, two multi-threaded executions of a code that collects elements into the bag might result in the elements being collected in different orders. | Since write operations are through adding elements to the end of the pinned vector via `push` and `extend`, two multi-threaded executions of a code that collects elements into the bag might result in the elements being collected in different orders. | This is the main goal of this collection, allowing to collect elements concurrently and in the correct order. Although this does not seem trivial; it can be achieved almost trivially when `ConcurrentOrderedBag` is used together with a [`ConcurrentIter`](https://crates.io/crates/orx-concurrent-iter). |
| `into_inner` | Once the concurrent collection is completed, the bag can safely and cheaply be converted to its underlying `PinnedVec`. | Once the concurrent collection is completed, the vec can safely be converted to its underlying `PinnedVec>`. Notice that elements are wrapped with a `ConcurrentOption` in order to provide thread safe concurrent read & write operations. | Growing through flexible setters allowing to write to any position, `ConcurrentOrderedBag` has the risk of containing gaps. `into_inner` call provides some useful metrics such as whether the number of elements pushed elements match the maximum index of the vector; however, it cannot guarantee that the bag is gap-free. The caller is required to take responsibility to unwrap to get the underlying `PinnedVec` through an `unsafe` call. |
|||||
## Performance Notes
### How many times and how long we spin?
There is only one waiting or spinning condition of the push and extend methods: whenever the underlying `PinnedVec` needs to grow. Note that growth with pinned vector is copy free. Therefore, when it spins, all it waits for is the allocation. Since number of growth is deterministic, so is the number of spins.
For instance, assume that we will push a total of 15_000 elements concurrently to an empty bag.
* Further assume we use the default `SplitVec<_, Doubling>` as the underlying pinned vector. Throughout the execution, we will allocate fragments of capacities [4, 8, 16, ..., 4096, 8192] which will lead to a total capacity of 16_380. In other words, we will allocate exactly 12 times during the entire execution.
* If we use a `SplitVec<_, Linear>` with constant fragment lengths of 1_024, we will allocate 15 equal capacity fragments.
* If we use the strict `FixedVec<_>`, we have to pre-allocate a safe amount and can never grow beyond this number. Therefore, there will never be any spinning.
### False Sharing
We need to be aware of the potential [false sharing](https://en.wikipedia.org/wiki/False_sharing) risk which might lead to significant performance degradation when we are filling the bag with one by one with [`ConcurrentBag::push`].
Performance degradation due to false sharing might be observed specifically when both of the following conditions hold:
* **small data**: data to be pushed is small, the more elements fitting in a cache line the bigger the risk,
* **little work**: multiple threads/cores are pushing to the concurrent bag with high frequency; i.e., very little or negligible work / time is required in between `push` calls.
The example above fits this situation. Each thread only performs one multiplication and addition in between pushing elements, and the elements to be pushed are small.
* `ConcurrentBag` assigns unique positions to each value to be pushed. There is no *true* sharing among threads in the position level.
* However, cache lines contain more than one position. One thread updating a particular position invalidates the entire cache line on an other thread.
* Threads end up frequently reloading cache lines instead of doing the actual work of writing elements to the bag. This might lead to a significant performance degradation.
### `extend` to Avoid False Sharing
Assume that we are filling a `ConcurrentBag` from n threads. At any given point, thread A calls `extend` by passing in an iterator which will yield 64 elements. Concurrent bag will reserve 64 consecutive positions for this extend call. Concurrent push or extend calls from other threads will not have access to these positions. Assuming that size of 64 elements is large enough:
* Thread A writing to these 64 positions will not invalidate cache lines of other threads. Similarly, other threads writing to their reserved positions will not invalidate thread A's cache line.
* Further, this will reduce the number of atomic updates compared to pushing elements one at a time.
Required change in the code from `push` to `extend` is not significant. The example above could be revised as follows to avoid the performance degrading of false sharing.
```rust
use orx_concurrent_bag::*;
let (num_threads, num_items_per_thread) = (4, 1_024);
let bag = ConcurrentBag::new();
let batch_size = 64;
let bag_ref = &bag;
std::thread::scope(|s| {
for i in 0..num_threads {
s.spawn(move || {
for j in (0..num_items_per_thread).step_by(batch_size) {
let iter = (j..(j + batch_size)).map(|j| i * 1000 + j);
bag_ref.extend(iter);
}
});
}
});
```
## Contributing
Contributions are welcome! If you notice an error, have a question or think something could be improved, please open an [issue](https://github.com/orxfun/orx-concurrent-bag/issues/new) or create a PR.
## License
This library is licensed under MIT license. See LICENSE for details.
## Concurrent Friend Collections
||[`ConcurrentBag`](https://crates.io/crates/orx-concurrent-bag)|[`ConcurrentVec`](https://crates.io/crates/orx-concurrent-vec)|[`ConcurrentOrderedBag`](https://crates.io/crates/orx-concurrent-ordered-bag)|
|---|---|---|---|
| Write | Guarantees that each element is written exactly once via `push` or `extend` methods | Guarantees that each element is written exactly once via `push` or `extend` methods | Different in two ways. First, a position can be written multiple times. Second, an arbitrary element of the bag can be written at any time at any order using `set_value` and `set_values` methods. This provides a great flexibility while moving the safety responsibility to the caller; hence, the set methods are `unsafe`. |
| Read | Mainly, a write-only collection. Concurrent reading of already pushed elements is through `unsafe` `get` and `iter` methods. The caller is required to avoid race conditions. | A write-and-read collection. Already pushed elements can safely be read through `get` and `iter` methods. | Not supported currently. Due to the flexible but unsafe nature of write operations, it is difficult to provide required safety guarantees as a caller. |
| Ordering of Elements | Since write operations are through adding elements to the end of the pinned vector via `push` and `extend`, two multi-threaded executions of a code that collects elements into the bag might result in the elements being collected in different orders. | Since write operations are through adding elements to the end of the pinned vector via `push` and `extend`, two multi-threaded executions of a code that collects elements into the bag might result in the elements being collected in different orders. | This is the main goal of this collection, allowing to collect elements concurrently and in the correct order. Although this does not seem trivial; it can be achieved almost trivially when `ConcurrentOrderedBag` is used together with a [`ConcurrentIter`](https://crates.io/crates/orx-concurrent-iter). |
| `into_inner` | Once the concurrent collection is completed, the bag can safely and cheaply be converted to its underlying `PinnedVec`. | Once the concurrent collection is completed, the vec can safely be converted to its underlying `PinnedVec>`. Notice that elements are wrapped with a `ConcurrentOption` in order to provide thread safe concurrent read & write operations. | Growing through flexible setters allowing to write to any position, `ConcurrentOrderedBag` has the risk of containing gaps. `into_inner` call provides some useful metrics such as whether the number of elements pushed elements match the maximum index of the vector; however, it cannot guarantee that the bag is gap-free. The caller is required to take responsibility to unwrap to get the underlying `PinnedVec` through an `unsafe` call. |
|||||
## Performance Notes
### How many times and how long we spin?
There is only one waiting or spinning condition of the push and extend methods: whenever the underlying `PinnedVec` needs to grow. Note that growth with pinned vector is copy free. Therefore, when it spins, all it waits for is the allocation. Since number of growth is deterministic, so is the number of spins.
For instance, assume that we will push a total of 15_000 elements concurrently to an empty bag.
* Further assume we use the default `SplitVec<_, Doubling>` as the underlying pinned vector. Throughout the execution, we will allocate fragments of capacities [4, 8, 16, ..., 4096, 8192] which will lead to a total capacity of 16_380. In other words, we will allocate exactly 12 times during the entire execution.
* If we use a `SplitVec<_, Linear>` with constant fragment lengths of 1_024, we will allocate 15 equal capacity fragments.
* If we use the strict `FixedVec<_>`, we have to pre-allocate a safe amount and can never grow beyond this number. Therefore, there will never be any spinning.
### False Sharing
We need to be aware of the potential [false sharing](https://en.wikipedia.org/wiki/False_sharing) risk which might lead to significant performance degradation when we are filling the bag with one by one with [`ConcurrentBag::push`].
Performance degradation due to false sharing might be observed specifically when both of the following conditions hold:
* **small data**: data to be pushed is small, the more elements fitting in a cache line the bigger the risk,
* **little work**: multiple threads/cores are pushing to the concurrent bag with high frequency; i.e., very little or negligible work / time is required in between `push` calls.
The example above fits this situation. Each thread only performs one multiplication and addition in between pushing elements, and the elements to be pushed are small.
* `ConcurrentBag` assigns unique positions to each value to be pushed. There is no *true* sharing among threads in the position level.
* However, cache lines contain more than one position. One thread updating a particular position invalidates the entire cache line on an other thread.
* Threads end up frequently reloading cache lines instead of doing the actual work of writing elements to the bag. This might lead to a significant performance degradation.
### `extend` to Avoid False Sharing
Assume that we are filling a `ConcurrentBag` from n threads. At any given point, thread A calls `extend` by passing in an iterator which will yield 64 elements. Concurrent bag will reserve 64 consecutive positions for this extend call. Concurrent push or extend calls from other threads will not have access to these positions. Assuming that size of 64 elements is large enough:
* Thread A writing to these 64 positions will not invalidate cache lines of other threads. Similarly, other threads writing to their reserved positions will not invalidate thread A's cache line.
* Further, this will reduce the number of atomic updates compared to pushing elements one at a time.
Required change in the code from `push` to `extend` is not significant. The example above could be revised as follows to avoid the performance degrading of false sharing.
```rust
use orx_concurrent_bag::*;
let (num_threads, num_items_per_thread) = (4, 1_024);
let bag = ConcurrentBag::new();
let batch_size = 64;
let bag_ref = &bag;
std::thread::scope(|s| {
for i in 0..num_threads {
s.spawn(move || {
for j in (0..num_items_per_thread).step_by(batch_size) {
let iter = (j..(j + batch_size)).map(|j| i * 1000 + j);
bag_ref.extend(iter);
}
});
}
});
```
## Contributing
Contributions are welcome! If you notice an error, have a question or think something could be improved, please open an [issue](https://github.com/orxfun/orx-concurrent-bag/issues/new) or create a PR.
## License
This library is licensed under MIT license. See LICENSE for details.