# Concurrent Growth Benchmark
The following experiments focus only on the concurrent growth or collection of the elements.
## Growth with ***push***
In the first part, *rayon*'s parallel iterator, and push methods of *AppendOnlyVec*, *boxcar::Vec* and *ConcurrentVec* are used to collect results from multiple threads. Further, different underlying pinned vectors of the *ConcurrentVec* are evaluated. You may find the details of the benchmarks at [benches/collect_with_push.rs](https://github.com/orxfun/orx-concurrent-vec/blob/main/benches/collect_with_push.rs).
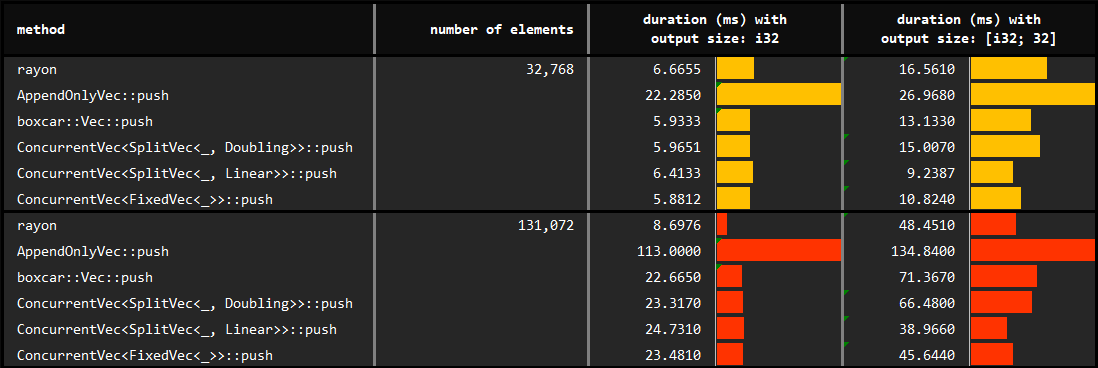 We observe that:
* The default `Doubling` growth strategy leads to efficient concurrent collection of results. Note that this variant does not require any input to construct.
* On the other hand, `Linear` growth strategy performs significantly better. Note that value of this argument means that each fragment of the underlying `SplitVec` will have a capacity of 2^12 (4096) elements. The underlying reason of improvement is potentially be due to less waste and could be preferred with minor knowledge of the data to be pushed.
* Finally, `Fixed` growth strategy is the least flexible and requires perfect knowledge about the hard-constrained capacity (will panic if we exceed). Since it does not outperform `Linear`, we do not necessarily prefer `Fixed` even if we have the perfect knowledge.
The performance can further be improved by using `extend` method instead of `push`. You may see results in the next subsection and details in the [performance notes](https://docs.rs/orx-concurrent-bag/2.3.0/orx_concurrent_bag/#section-performance-notes) of `ConcurrentBag` which has similar characteristics.
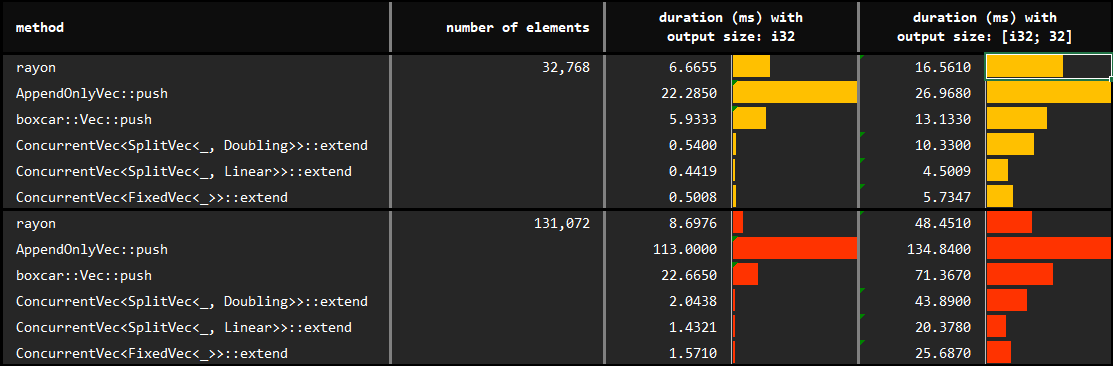
## Growth with ***extend***
The only difference in this follow up experiment is that we use `extend` rather than `push` with *ConcurrentVec*. You may find the details of the benchmarks at [benches/collect_with_extend.rs](https://github.com/orxfun/orx-concurrent-vec/blob/main/benches/collect_with_extend.rs).
The expectation is that this approach will solve the performance degradation due to false sharing, which turns out to be true:
* Extending rather than pushing might double the growth performance.
* There is not a significant difference between extending by batches of 64 elements or batches of 65536 elements. We do not need a well tuned number, a large enough batch size seems to be just fine.
* Not all scenarios allow to extend in batches; however, the significant performance improvement makes it preferable whenever possible.
We observe that:
* The default `Doubling` growth strategy leads to efficient concurrent collection of results. Note that this variant does not require any input to construct.
* On the other hand, `Linear` growth strategy performs significantly better. Note that value of this argument means that each fragment of the underlying `SplitVec` will have a capacity of 2^12 (4096) elements. The underlying reason of improvement is potentially be due to less waste and could be preferred with minor knowledge of the data to be pushed.
* Finally, `Fixed` growth strategy is the least flexible and requires perfect knowledge about the hard-constrained capacity (will panic if we exceed). Since it does not outperform `Linear`, we do not necessarily prefer `Fixed` even if we have the perfect knowledge.
The performance can further be improved by using `extend` method instead of `push`. You may see results in the next subsection and details in the [performance notes](https://docs.rs/orx-concurrent-bag/2.3.0/orx_concurrent_bag/#section-performance-notes) of `ConcurrentBag` which has similar characteristics.
## Growth with ***extend***
The only difference in this follow up experiment is that we use `extend` rather than `push` with *ConcurrentVec*. You may find the details of the benchmarks at [benches/collect_with_extend.rs](https://github.com/orxfun/orx-concurrent-vec/blob/main/benches/collect_with_extend.rs).
The expectation is that this approach will solve the performance degradation due to false sharing, which turns out to be true:
* Extending rather than pushing might double the growth performance.
* There is not a significant difference between extending by batches of 64 elements or batches of 65536 elements. We do not need a well tuned number, a large enough batch size seems to be just fine.
* Not all scenarios allow to extend in batches; however, the significant performance improvement makes it preferable whenever possible.