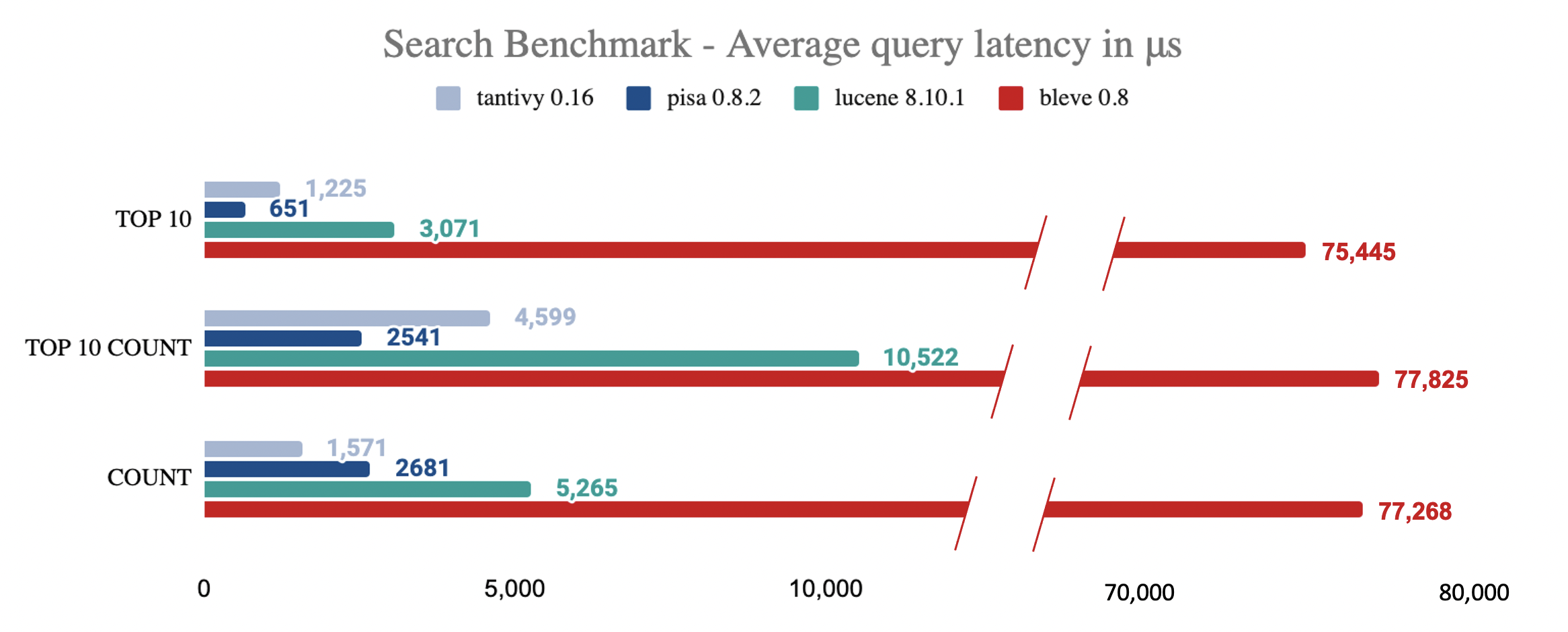
 Details about the benchmark can be found at this [repository](https://github.com/quickwit-oss/search-benchmark-game).
# Features
- Full-text search
- Configurable tokenizer (stemming available for 17 Latin languages) with third party support for Chinese ([tantivy-jieba](https://crates.io/crates/tantivy-jieba) and [cang-jie](https://crates.io/crates/cang-jie)), Japanese ([lindera](https://github.com/lindera-morphology/lindera-tantivy), [Vaporetto](https://crates.io/crates/vaporetto_tantivy), and [tantivy-tokenizer-tiny-segmenter](https://crates.io/crates/tantivy-tokenizer-tiny-segmenter)) and Korean ([lindera](https://github.com/lindera-morphology/lindera-tantivy) + [lindera-ko-dic-builder](https://github.com/lindera-morphology/lindera-ko-dic-builder))
- Fast (check out the :racehorse: :sparkles: [benchmark](https://tantivy-search.github.io/bench/) :sparkles: :racehorse:)
- Tiny startup time (<10ms), perfect for command-line tools
- BM25 scoring (the same as Lucene)
- Natural query language (e.g. `(michael AND jackson) OR "king of pop"`)
- Phrase queries search (e.g. `"michael jackson"`)
- Incremental indexing
- Multithreaded indexing (indexing English Wikipedia takes < 3 minutes on my desktop)
- Mmap directory
- SIMD integer compression when the platform/CPU includes the SSE2 instruction set
- Single valued and multivalued u64, i64, and f64 fast fields (equivalent of doc values in Lucene)
- `&[u8]` fast fields
- Text, i64, u64, f64, dates, ip, bool, and hierarchical facet fields
- Compressed document store (LZ4, Zstd, None)
- Range queries
- Faceted search
- Configurable indexing (optional term frequency and position indexing)
- JSON Field
- Aggregation Collector: histogram, range buckets, average, and stats metrics
- LogMergePolicy with deletes
- Searcher Warmer API
- Cheesy logo with a horse
## Non-features
Distributed search is out of the scope of Tantivy, but if you are looking for this feature, check out [Quickwit](https://github.com/quickwit-oss/quickwit/).
# Getting started
Tantivy works on stable Rust and supports Linux, macOS, and Windows.
- [Tantivy's simple search example](https://tantivy-search.github.io/examples/basic_search.html)
- [tantivy-cli and its tutorial](https://github.com/quickwit-oss/tantivy-cli) - `tantivy-cli` is an actual command-line interface that makes it easy for you to create a search engine,
index documents, and search via the CLI or a small server with a REST API.
It walks you through getting a Wikipedia search engine up and running in a few minutes.
- [Reference doc for the last released version](https://docs.rs/tantivy/)
# How can I support this project?
There are many ways to support this project.
- Use Tantivy and tell us about your experience on [Discord](https://discord.gg/MT27AG5EVE) or by email (paul.masurel@gmail.com)
- Report bugs
- Write a blog post
- Help with documentation by asking questions or submitting PRs
- Contribute code (you can join [our Discord server](https://discord.gg/MT27AG5EVE))
- Talk about Tantivy around you
# Contributing code
We use the GitHub Pull Request workflow: reference a GitHub ticket and/or include a comprehensive commit message when opening a PR.
Feel free to update CHANGELOG.md with your contribution.
## Tokenizer
When implementing a tokenizer for tantivy depend on the `tantivy-tokenizer-api` crate.
## Clone and build locally
Tantivy compiles on stable Rust.
To check out and run tests, you can simply run:
```bash
git clone https://github.com/quickwit-oss/tantivy.git
cd tantivy
cargo test
```
# Companies Using Tantivy
Details about the benchmark can be found at this [repository](https://github.com/quickwit-oss/search-benchmark-game).
# Features
- Full-text search
- Configurable tokenizer (stemming available for 17 Latin languages) with third party support for Chinese ([tantivy-jieba](https://crates.io/crates/tantivy-jieba) and [cang-jie](https://crates.io/crates/cang-jie)), Japanese ([lindera](https://github.com/lindera-morphology/lindera-tantivy), [Vaporetto](https://crates.io/crates/vaporetto_tantivy), and [tantivy-tokenizer-tiny-segmenter](https://crates.io/crates/tantivy-tokenizer-tiny-segmenter)) and Korean ([lindera](https://github.com/lindera-morphology/lindera-tantivy) + [lindera-ko-dic-builder](https://github.com/lindera-morphology/lindera-ko-dic-builder))
- Fast (check out the :racehorse: :sparkles: [benchmark](https://tantivy-search.github.io/bench/) :sparkles: :racehorse:)
- Tiny startup time (<10ms), perfect for command-line tools
- BM25 scoring (the same as Lucene)
- Natural query language (e.g. `(michael AND jackson) OR "king of pop"`)
- Phrase queries search (e.g. `"michael jackson"`)
- Incremental indexing
- Multithreaded indexing (indexing English Wikipedia takes < 3 minutes on my desktop)
- Mmap directory
- SIMD integer compression when the platform/CPU includes the SSE2 instruction set
- Single valued and multivalued u64, i64, and f64 fast fields (equivalent of doc values in Lucene)
- `&[u8]` fast fields
- Text, i64, u64, f64, dates, ip, bool, and hierarchical facet fields
- Compressed document store (LZ4, Zstd, None)
- Range queries
- Faceted search
- Configurable indexing (optional term frequency and position indexing)
- JSON Field
- Aggregation Collector: histogram, range buckets, average, and stats metrics
- LogMergePolicy with deletes
- Searcher Warmer API
- Cheesy logo with a horse
## Non-features
Distributed search is out of the scope of Tantivy, but if you are looking for this feature, check out [Quickwit](https://github.com/quickwit-oss/quickwit/).
# Getting started
Tantivy works on stable Rust and supports Linux, macOS, and Windows.
- [Tantivy's simple search example](https://tantivy-search.github.io/examples/basic_search.html)
- [tantivy-cli and its tutorial](https://github.com/quickwit-oss/tantivy-cli) - `tantivy-cli` is an actual command-line interface that makes it easy for you to create a search engine,
index documents, and search via the CLI or a small server with a REST API.
It walks you through getting a Wikipedia search engine up and running in a few minutes.
- [Reference doc for the last released version](https://docs.rs/tantivy/)
# How can I support this project?
There are many ways to support this project.
- Use Tantivy and tell us about your experience on [Discord](https://discord.gg/MT27AG5EVE) or by email (paul.masurel@gmail.com)
- Report bugs
- Write a blog post
- Help with documentation by asking questions or submitting PRs
- Contribute code (you can join [our Discord server](https://discord.gg/MT27AG5EVE))
- Talk about Tantivy around you
# Contributing code
We use the GitHub Pull Request workflow: reference a GitHub ticket and/or include a comprehensive commit message when opening a PR.
Feel free to update CHANGELOG.md with your contribution.
## Tokenizer
When implementing a tokenizer for tantivy depend on the `tantivy-tokenizer-api` crate.
## Clone and build locally
Tantivy compiles on stable Rust.
To check out and run tests, you can simply run:
```bash
git clone https://github.com/quickwit-oss/tantivy.git
cd tantivy
cargo test
```
# Companies Using Tantivy
![]()
![]()
![]()
![]()
![]()
![]()
![]()