bintensors
| Crates.io | bintensors |
| lib.rs | bintensors |
| version | 0.1.1 |
| created_at | 2025-04-02 10:40:33.10984+00 |
| updated_at | 2025-04-30 20:41:41.700834+00 |
| description | Bintensors is a high-performance binary tensor serialization format designed to be faster eliminating use of JSON serialization metadata. |
| homepage | |
| repository | https://github.com/GnosisFoundation/bintensors |
| max_upload_size | |
| id | 1616335 |
| size | 131,210 |
 Luca Vivona (LVivona)
Luca Vivona (LVivona)
documentation
README




Another file format for storing your models and "tensors", in a binary encoded format, designed for speed with zero-copy access.
Installation
Cargo
You can add bintensors to your cargo by using cargo add:
cargo add bintensors
Pip
You can install bintensors via the pip manager:
pip install bintensors
From source
For the sources, you need Rust
# Install Rust
curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh
# Make sure it's up to date and using stable channel
rustup update
git clone https://github.com/GnosisFoundation/bintensors
cd bintensors/bindings/python
pip install setuptools_rust
# install
pip install -e .
Getting Started
import torch
from bintensors import safe_open
from bintensors.torch import save_file
tensors = {
"weight1": torch.zeros((1024, 1024)),
"weight2": torch.zeros((1024, 1024))
}
save_file(tensors, "model.bt")
tensors = {}
with safe_open("model.bt", framework="pt", device="cpu") as f:
for key in f.keys():
tensors[key] = f.get_tensor(key)
Lets assume we want to handle file in rust
use bintensors::BinTensors;
use memmap2::MmapOptions;
use std::fs::File;
let filename = "model.bt";
use std::io::Write;
let serialized = b"\x18\x00\x00\x00\x00\x00\x00\x00\x00\x01\x08weight_1\x00\x02\x02\x02\x00\x04 \x00\x00\x00\x00";
File::create(&filename).unwrap().write(serialized).unwrap();
let file = File::open(filename).unwrap();
let buffer = unsafe { MmapOptions::new().map(&file).unwrap() };
let tensors = BinTensors::deserialize(&buffer).unwrap();
let tensor = tensors
.tensor("weight_1");
std::fs::remove_file(filename).unwrap()
Overview
This project initially started as an exploration of the safetensors file format, primarily to gain a deeper understanding of an ongoing parent project of mine, on distributing models over a subnet. While the format itself is relatively intuitive and well-implemented, it leads to some consideration regarding the use of serde_json for storing metadata.
Although the decision by the Hugging Face safetensors development team to utilize serde_json is understandable, such as for file readability, I questioned the necessity of this approach. Given the complexity of modern models, which can contain thousands of layers, it seems inefficient to store metadata in a human-readable format. In many instances, such metadata might be more appropriately stored in a more compact, optimized format.
TDLR why not just use a more otimized serde such as bincode.
Observable Changes
 Serde figure from safetensors generated by cargo bench
Serde figure from safetensors generated by cargo bench
 Serde figure from bintensors generated by cargo bench
Serde figure from bintensors generated by cargo bench
Incorporating the bincode library led to a significant performance boost in deserialization, nearly tripling its speed—an improvement that was somewhat expected. Benchmarking code can be found in bintensors/bench/benchmark.rs, where we conducted two separate tests per repository, comparing the serialization performance of model tests in safesensors and bintensors within the Rust-only implementation. The results, as shown in the figure above, highlight the substantial gains achieved.
To better understand the factors behind this improvement, we analyzed the call stack, comparing the performance characteristics of serde_json and bincode. To facilitate this, we generated a flame graph to visualize execution paths and identify potential bottlenecks in the serde_json deserializer. The findings are illustrated in the figures below.
This experiment was conducted on macOS, and while the results are likely consistent across platforms, I plan to extend the analysis to other operating systems for further validation.

Serde figure from bintensors generated by flamepgraph & inferno

Serde figure from safetensors generated by flamepgraph & inferno
Format
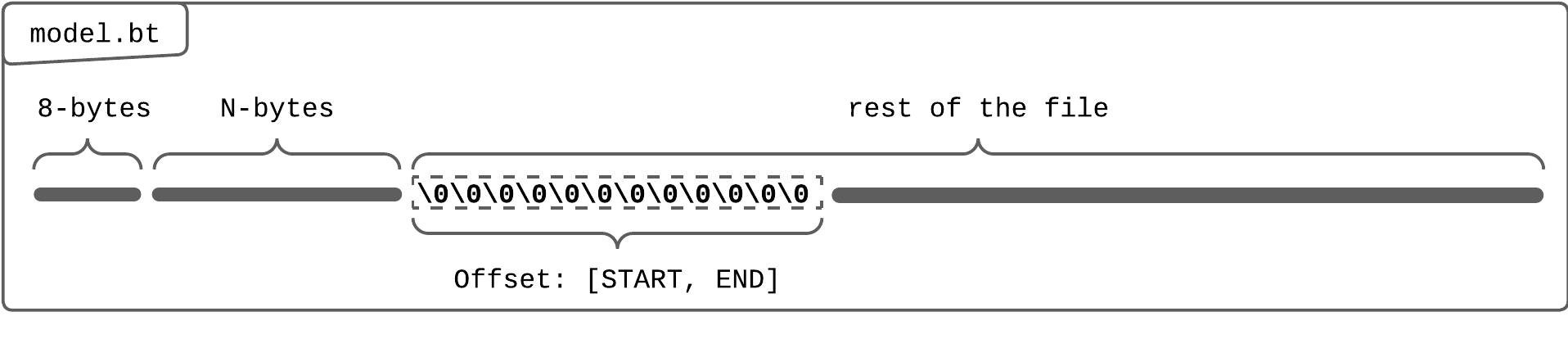
Visual representation of bintensors (bt) file format
In this section, I suggest creating a small model and opening a hex dump to better visually decouple it while we go over the high level of the bintensors file format. For a more in-depth understanding of the encoding, I would glance at specs.
The file format is divided into three sections:
Header Size:
- 8 bytes: A little-endian, unsigned 64-bit integer that is $2^{63 - 1}$ representing the size of the header, though there is a cap on of 100Mb similar to
safetensorsbut that may be changed later in the future.
Header Data
- N bytes: A dynamically serialized table, encoded in a condensed binary format for efficient tensor lookups.
- Contains a map of string-to-string pairs. Note that arbitrary JSON structures are not permitted; all values must be strings.
- The header data deserialization decoding capacity is 100Mb.
Tensor Data
- A sequence of bytes representing the layered tensor data.
Notes
- Duplicate keys are disallowed. Not all parsers may respect this.
- Tensor values are not checked against, in particular NaN and +/-Inf could be in the file
- Empty tensors (tensors with 1 dimension being 0) are allowed. They are not storing any data in the databuffer, yet retaining size in the header. They don’t really bring a lot of values but are accepted since they are valid tensors from traditional tensor libraries perspective (torch, tensorflow, numpy, ..).
- The byte buffer needs to be entirely indexed, and cannot contain holes. This prevents the creation of polyglot files.
- Endianness: Little-endian. moment.
- Order: ‘C’ or row-major.
- Checksum over the bytes, giving the file a unique identiy.
- Allows distributive networks to validate distributed layers checksums.
Benefits
Since this is a simple fork of safetensors it holds similar propeties that safetensors holds.
- Preformance boost: Bintensors provides a nice preformace boost to the growning ecosystem, of model stroage.
- Prevent DOS attacks: To ensure robust security in our file format, we've implemented anti-DOS protections while maintaining compatibility with the original format's approach. The header buffer is strictly limited to 100MB, preventing resource exhaustion attacks via oversized metadata. Additionally, we enforce strict address boundary validation to guarantee non-overlapping tensor allocations, ensuring memory consumption never exceeds the file's actual size during loading operations. This two-pronged approach effectively mitigates both memory exhaustion vectors and buffer overflow opportunities.
- Faster load: PyTorch seems to be the fastest file to load out in the major ML formats. However, it does seem to have an extra copy on CPU, which we can bypass in this lib by using torch.UntypedStorage.from_file. Currently, CPU loading times are extremely fast with this lib compared to pickle. GPU loading times are as fast or faster than PyTorch equivalent. Loading first on CPU with memmapping with torch, and then moving all tensors to GPU seems to be faster too somehow (similar behavior in torch pickle)
- Lazy loading: in distributed (multi-node or multi-gpu) settings, it’s nice to be able to load only part of the tensors on the various models. For BLOOM using this format enabled to load the model on 8 GPUs from 10mn with regular PyTorch weights down to 45s. This really speeds up feedbacks loops when developing on the model. For instance you don’t have to have separate copies of the weights when changing the distribution strategy (for instance Pipeline Parallelism vs Tensor Parallelism).
Licence: MIT