griddle
| Crates.io | griddle |
| lib.rs | griddle |
| version | 0.6.0 |
| created_at | 2020-06-30 01:05:54.869754+00 |
| updated_at | 2024-10-19 09:10:42.324412+00 |
| description | A HashMap variant that spreads resize load across inserts |
| homepage | |
| repository | https://github.com/jonhoo/griddle.git |
| max_upload_size | |
| id | 259603 |
| size | 359,617 |
 Jon Gjengset (jonhoo)
Jon Gjengset (jonhoo)
documentation
README

![]()
![]()
![]()
A HashMap variant that spreads resize load across inserts.
Most hash table implementations (including hashbrown, the one in
Rust's standard library) must occasionally "resize" the backing memory
for the map as the number of elements grows. This means allocating a new
table (usually of twice the size), and moving all the elements from the
old table to the new one. As your table gets larger, this process takes
longer and longer.
For most applications, this behavior is fine — if some very small number of inserts take longer than others, the application won't even notice. And if the map is relatively small anyway, even those "slow" inserts are quite fast. Similarly, if your map grow for a while, and then stops growing, the "steady state" of your application won't see any resizing pauses at all.
Where resizing becomes a problem is in applications that use maps to keep ever-growing state where tail latency is important. At large scale, it is simply not okay for one map insert to take 30 milliseconds when most take below a microsecond. Worse yet, these resize pauses can compound to create significant spikes in tail latency.
This crate implements a technique referred to as "incremental resizing", in contrast to the common "all-at-once" approached outlined above. At its core, the idea is pretty simple: instead of moving all the elements to the resized map immediately, move a couple each time an insert happens. This spreads the cost of moving the elements so that each insert becomes a little slower until the resize has finished, instead of one insert becoming a lot slower.
This approach isn't free, however. While the resize is going on, the old table must be kept around (so memory isn't reclaimed immediately), and all reads must check both the old and new map, which makes them slower. Only once the resize completes is the old table reclaimed and full read performance restored.
To help you decide whether this implementation is right for you, here's a handy reference for how this implementation compares to the standard library map:
- Inserts all take approximately the same time. After a resize, they will be slower for a while, but only by a relatively small factor.
- Memory is not reclaimed immediately upon resize.
- Reads and removals of old or missing keys are slower for a while after a resize.
- The incremental map is slightly larger on the stack.
- The "efficiency" of the resize is slightly lower as the all-at-once resize moves the items from the small table to the large one in batch, whereas the incremental does a series of inserts.
Benchmarks
There is a silly, but illustrative benchmark in benches/vroom.rs. It
just runs lots of inserts back-to-back, and measures how long each one
takes. The problem quickly becomes apparent:
$ cargo bench --bench vroom > vroom.dat
hashbrown::HashMap max: 38.335088ms, mean: 94ns
griddle::HashMap max: 1.846561ms, mean: 126ns
You can see that the standard library implementation (through
hashbrown) has some pretty severe latency spikes. This is more readily
visible through a timeline latency plot (misc/vroom.plt):
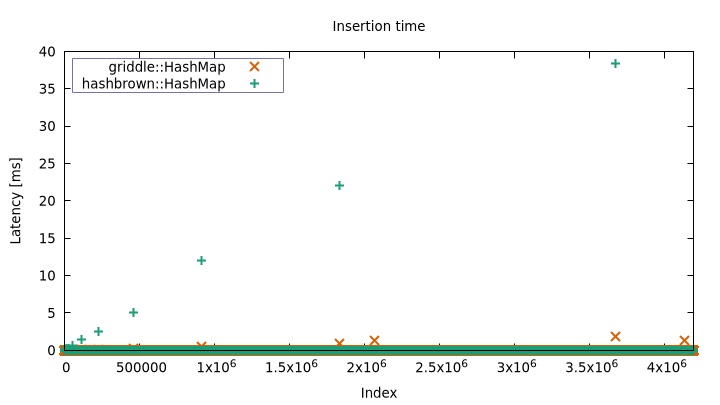
Resizes happen less frequently as the map grows, but they also take longer when they occur. With griddle, those spikes are mostly gone. There is a small linear component left, which I believe comes from the work required to find the buckets that hold elements that must be moved.
Implementation
Griddle uses the
hashbrown::raw
API, which allows it to take advantage of all the awesome work that has
gone into making hashbrown as fast as it is. The key different parts
of griddle live in src/raw/mod.rs. The raw API was removed in
hashbrown 0.15, so
Griddle is stuck on 0.14 for now.
Griddle aims to stick as closely to hashbrown as it can, both in terms
of code and API. src/map.rs and src/set.rs are virtually identical
to the equivalent files in hashbrown (I encourage you to diff them!),
without only some (currently;
#4) unsupported API
removed.
Why "griddle"?
You can amortize the cost of making hashbrowns by using a griddle..?
License
Licensed under either of
- Apache License, Version 2.0 (LICENSE-APACHE or http://www.apache.org/licenses/LICENSE-2.0)
- MIT license (LICENSE-MIT or http://opensource.org/licenses/MIT)
at your option.
Contribution
Unless you explicitly state otherwise, any contribution intentionally submitted for inclusion in the work by you, as defined in the Apache-2.0 license, shall be dual licensed as above, without any additional terms or conditions.