iron_runtime
| Crates.io | iron_runtime |
| lib.rs | iron_runtime |
| version | 0.4.0 |
| created_at | 2025-11-25 17:03:33.141489+00 |
| updated_at | 2025-12-18 09:32:17.218022+00 |
| description | Agent runtime with LLM request routing and translation |
| homepage | |
| repository | https://github.com/.../iron_runtime |
| max_upload_size | |
| id | 1950087 |
| size | 173,423 |
 Wandalen (Wandalen)
Wandalen (Wandalen)
documentation
README
iron_runtime
Agent orchestration and Python bridge for AI agent execution. Provides LlmRouter - a local proxy server for transparent LLM API key management with OpenAI and Anthropic support.
![]()
[!IMPORTANT] Audience: Platform contributors developing the iron_runtime Rust crate. End Users: See iron_sdk documentation - just
pip install iron-sdk
Installation
Python Library (pip)
The Python library is built using maturin and PyO3.
Prerequisites:
- Python 3.9+
- Rust toolchain (rustup)
- uv package manager (
curl -LsSf https://astral.sh/uv/install.sh | sh)
Development Install:
cd module/iron_runtime
# Install dependencies and setup environment
uv sync # Automatically creates .venv and installs all dev dependencies
# Build and install in development mode
uv run maturin develop
# Verify installation
uv run python -c "from iron_cage import LlmRouter; print('OK')"
Build Wheel:
# Build wheel for distribution
uv run maturin build --release
# Wheel will be in target/wheels/
ls target/wheels/
# iron_cage-0.1.0-cp38-abi3-*.whl
Rust Crate
[dependencies]
iron_runtime = { path = "../iron_runtime" }
Quick Start (Python)
Server Mode (default)
Keys are fetched from Iron Cage server:
import os
from iron_cage import LlmRouter
from openai import OpenAI
router = LlmRouter(
api_key=os.environ["IC_TOKEN"],
server_url=os.environ["IC_SERVER"],
)
client = OpenAI(base_url=router.base_url, api_key=router.api_key)
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": "Hello!"}],
)
print(response.choices[0].message.content)
router.stop()
Direct Mode (with local API key)
Use your own API key with optional budget tracking and analytics sync:
from iron_cage import LlmRouter
from openai import OpenAI
router = LlmRouter(
provider_key=os.environ["OPENAI_API_KEY"], # Your actual API key
api_key=os.environ["IC_TOKEN"], # For analytics auth
server_url=os.environ["IC_SERVER"], # Analytics server
budget=10.0, # $10 budget limit
)
client = OpenAI(base_url=router.base_url, api_key=router.api_key)
# Make requests...
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": "Hello!"}],
)
# Check spending
if router.budget_status:
spent, limit = router.budget_status
print(f"Spent: ${spent:.4f} / ${limit:.2f}")
router.stop() # Flushes analytics to server
With Anthropic:
from iron_cage import LlmRouter
from anthropic import Anthropic
router = LlmRouter(api_key=ic_token, server_url=ic_server)
# Anthropic API doesn't use /v1 suffix
client = Anthropic(
base_url=router.base_url.replace("/v1", ""),
api_key=router.api_key,
)
response = client.messages.create(
model="claude-sonnet-4-20250514",
max_tokens=100,
messages=[{"role": "user", "content": "Hello!"}],
)
print(response.content[0].text)
router.stop()
Gateway Mode (OpenAI client for Claude):
Use the same OpenAI client for both OpenAI and Claude models - just change the model name:
from iron_cage import LlmRouter
from openai import OpenAI
router = LlmRouter(api_key=ic_token, server_url=ic_server)
client = OpenAI(base_url=router.base_url, api_key=router.api_key)
# Same client works for both providers!
response = client.chat.completions.create(
model="claude-sonnet-4-20250514", # Claude model with OpenAI client!
messages=[
{"role": "system", "content": "You are helpful."},
{"role": "user", "content": "Hello!"}
],
max_tokens=100
)
print(response.choices[0].message.content) # OpenAI format response
router.stop()
The router automatically:
- Detects Claude model → routes to Anthropic API
- Translates request (OpenAI → Anthropic format)
- Translates response (Anthropic → OpenAI format)
Context Manager:
with LlmRouter(api_key=token, server_url=url) as router:
client = OpenAI(base_url=router.base_url, api_key=router.api_key)
# ... use client
# Router automatically stops on exit
Architecture
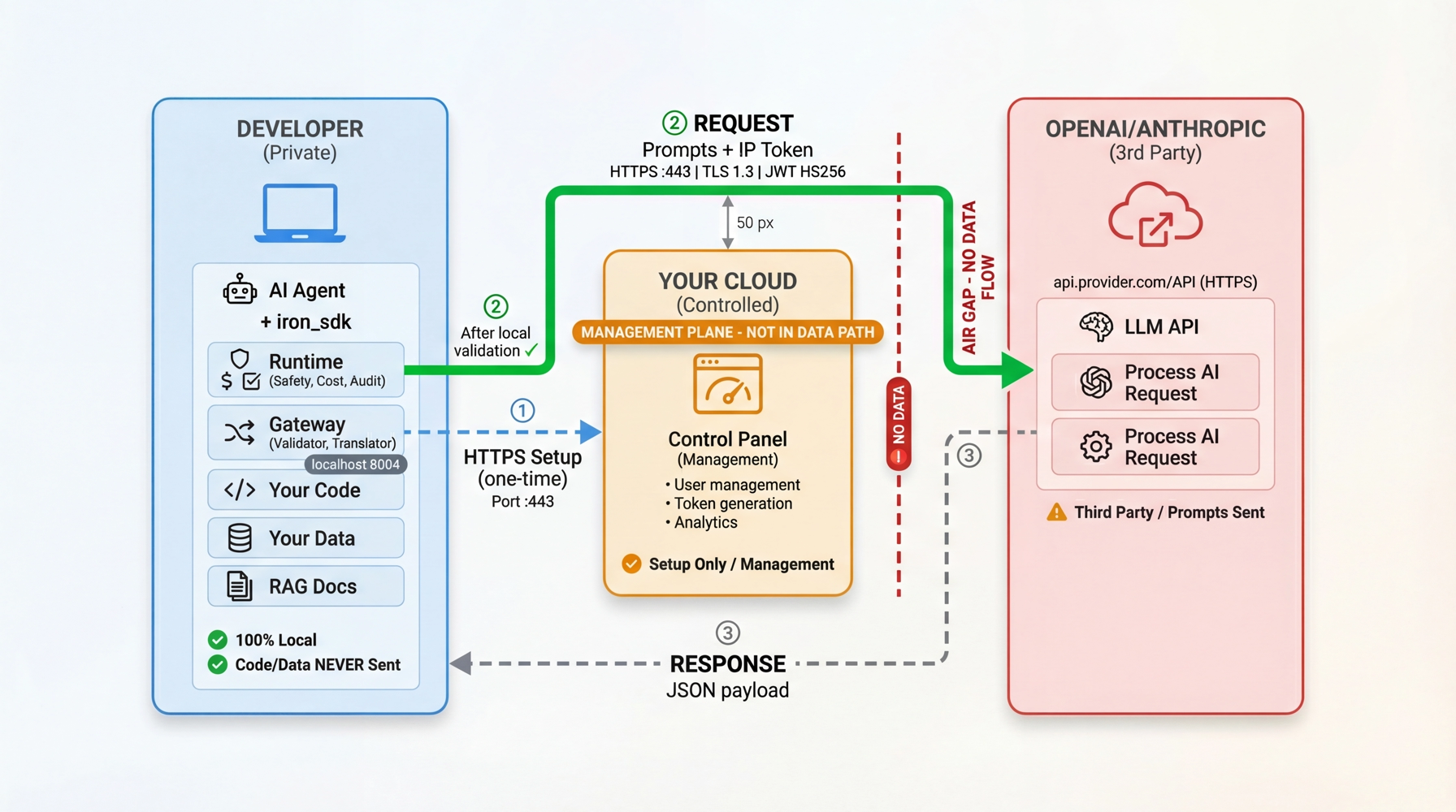
Visual Guide:
- Left (Developer Zone): Agent, iron_sdk, Runtime (Safety/Cost/Audit), Gateway - 100% local
- Middle (Management Plane): Control Panel - NOT in data path
- Right (Provider Zone): LLM provider receives only prompts with IP Token
See root readme for detailed architecture explanation.
API Reference
LlmRouter
Local HTTP proxy server for LLM API requests with automatic key management.
Constructor:
LlmRouter(
api_key: str, # Iron Cage token (IC_TOKEN)
server_url: str, # Iron Cage server URL
cache_ttl_seconds: int = 300, # Key cache TTL
provider_key: str | None = None, # Direct mode: your API key
budget: float | None = None, # Direct mode: spending limit in USD
)
Modes:
- Server mode (default):
provider_keynot set - keys fetched from server - Direct mode:
provider_keyset - use your own API key with local budget tracking
Properties:
| Property | Type | Description |
|---|---|---|
base_url |
str |
Proxy URL for OpenAI client (http://127.0.0.1:{port}/v1) |
api_key |
str |
IC token for client authentication |
port |
int |
Port the proxy is listening on |
provider |
str |
Auto-detected provider ("openai" or "anthropic") |
is_running |
bool |
Whether the proxy is running |
budget_status |
`tuple[float, float] | None` |
Methods:
| Method | Description |
|---|---|
stop() |
Stop the proxy server (flushes analytics in direct mode) |
__enter__() / __exit__() |
Context manager support |
Analytics (Direct Mode):
In direct mode, the router automatically:
- Tracks spending per request using iron_cost pricing
- Records analytics events (completed/failed requests)
- Syncs events to server every 5 seconds
- Flushes remaining events on
stop()
Provider Auto-Detection:
- API keys starting with
sk-ant-→ Anthropic - All other
sk-*keys → OpenAI
Testing
Build iron_cage inside a uv virtualenv
cd module/iron_runtimeuv sync --extra dev --extra examples(installs pytest + OpenAI/Anthropic clients into.venv)uv run maturin develop(builds theiron_cageextension into the venv)- Verify:
uv run python - <<'PY'\nfrom iron_cage import LlmRouter; print('iron_cage import OK', LlmRouter)\nPY
Fresh venv + server E2E (step-by-step)
From repo root:
uv venv .venv && source .venv/bin/activate(or deactivate any other venv to avoid theVIRTUAL_ENV ... does not matchwarning)cd module/iron_runtimeuv sync --extra dev --extra examplesuv run maturin develop(warning aboutpython/.../iron_runtimeis expected; optional:pip install patchelfto silence rpath warning)- Sanity check:
uv run python - <<'PY'\nfrom iron_cage import LlmRouter; print('import OK', LlmRouter)\nPY - Run server E2E:
IC_TOKEN=ic_xxx IC_SERVER=http://localhost:3001 uv run pytest python/tests/test_llm_router_e2e.py -v- For Rust logs, add
-sandRUST_LOG=trace.
- For Rust logs, add
Run Python tests
- E2E suites auto-skip without credentials. Set
IC_TOKEN+IC_SERVERfor server-mode tests; setOPENAI_API_KEYorANTHROPIC_API_KEYfor direct-mode budget tests (these spend real money—use tiny budgets). - Server path:
IC_TOKEN=ic_xxx IC_SERVER=http://localhost:3001 uv run pytest python/tests/test_llm_router_e2e.py -v - Direct path:
OPENAI_API_KEY=sk-xxx uv run pytest python/tests/test_budget_e2e.py -k openai -v - Full sweep (requires all credentials):
IC_TOKEN=... IC_SERVER=... OPENAI_API_KEY=... uv run pytest python/tests -v - Add
RUST_LOG=infoto see router logs during test runs.
Run Rust tests
cd module/iron_runtime
cargo test -p iron_runtime
Manual examples
uv run python python/examples/test_manual.py openai # Test OpenAI API
uv run python python/examples/test_manual.py anthropic # Test Anthropic API
uv run python python/examples/test_manual.py gateway # Test OpenAI client → Claude
Example (Rust)
use iron_runtime::LlmRouter;
// Create router
let mut router = LlmRouter::create(
api_key.to_string(),
server_url.to_string(),
300, // cache TTL
)?;
let base_url = router.get_base_url();
println!("Proxy running at: {}", base_url);
// Use with HTTP client...
router.shutdown();
Scope & Boundaries
Responsibilities: Bridges Python AI agents with Rust-based safety, cost, and reliability infrastructure via PyO3. Provides LlmRouter for transparent API key management and request proxying. Manages agent lifecycle (spawn, monitor, shutdown), intercepts LLM calls for policy enforcement, coordinates tokio async runtime, and provides WebSocket server for real-time dashboard updates.
In Scope:
- Python-Rust FFI via PyO3 (agent execution bridge)
- LlmRouter - Local proxy for LLM API requests
- Multi-provider support (OpenAI, Anthropic) with auto-detection
- Agent lifecycle management (spawn, monitor, shutdown)
- LLM call interception and policy enforcement
- Tokio async runtime coordination
- WebSocket server for dashboard real-time updates
- Configuration management (CLI args to RuntimeConfig)
- Single-agent execution model
Out of Scope:
- REST API endpoints (see iron_control_api)
- PII detection logic (see iron_safety)
- Cost calculation (see iron_cost)
- Circuit breaker patterns (see iron_reliability)
- Token management (see iron_token_manager)
- State persistence (see iron_runtime_state)
- Multi-agent orchestration (future)
- Distributed runtime (future)
Directory Structure
Source Files
| File | Responsibility |
|---|---|
| lib.rs | Core runtime for AI agent execution |
| llm_router/ | LLM Router - Local proxy for LLM API requests |
Notes:
- Entries marked 'TBD' require manual documentation
- Entries marked '⚠️ ANTI-PATTERN' should be renamed to specific responsibilities
License
Apache-2.0