pav_regression
| Crates.io | pav_regression |
| lib.rs | pav_regression |
| version | 0.6.1 |
| created_at | 2021-02-24 21:26:36.818577+00 |
| updated_at | 2025-10-18 21:58:46.957925+00 |
| description | The pair adjacent violators algorithm for isotonic regression |
| homepage | https://github.com/sanity/pav.rs |
| repository | https://github.com/sanity/pav.rs |
| max_upload_size | |
| id | 360127 |
| size | 42,348 |
 Ian Clarke (sanity)
Ian Clarke (sanity)
documentation
README
Pair Adjacent Violators for Rust
![]()

Overview
An implementation of the Pair Adjacent Violators algorithm for isotonic regression. Note this algorithm is also known as "Pool Adjacent Violators".
What is "Isotonic Regression" and why should I care?
Imagine you have two variables, x and y, and you don't know the relationship between them, but you know that if x increases then y will increase, and if x decreases then y will decrease. Alternatively it may be the opposite, if x increases then y decreases, and if x decreases then y increases.
Examples of such isotonic or monotonic relationships include:
- x is the pressure applied to the accelerator in a car, y is the acceleration of the car (acceleration increases as more pressure is applied)
- x is the rate at which a web server is receiving HTTP requests, y is the CPU usage of the web server (server CPU usage will increase as the request rate increases)
- x is the price of an item, and y is the probability that someone will buy it (this would be a decreasing relationship, as x increases y decreases)
These are all examples of an isotonic relationship between two variables, where the relationship is likely to be more complex than linear.
So we know the relationship between x and y is isotonic, and let's also say that we've been able to collect data about actual x and y values that occur in practice.
What we'd really like to be able to do is estimate, for any given x, what y will be, or alternatively for any given y, what x would be required.
But of course real-world data is noisy, and is unlikely to be strictly isotonic, so we want something that allows us to feed in this raw noisy data, figure out the actual relationship between x and y, and then use this to allow us to predict y given x, or to predict what value of x will give us a particular value of y. This is the purpose of the pair-adjacent-violators algorithm.
...and why should I care?
Using the examples I provide above:
- A self-driving car could use it to learn how much pressure to apply to the accelerator to give a desired amount of acceleration
- An autoscaling system could use it to help predict how many web servers they need to handle a given amount of web traffic
- A retailer could use it to choose a price for an item that maximizes their profit (aka "yield optimization")
Isotonic regression in online advertising
If you have an hour to spare, and are interested in learning more about how online advertising works - you should check out this lecture that I gave in 2015 where I explain how we were able to use pair adjacent violators to solve some fun problems.
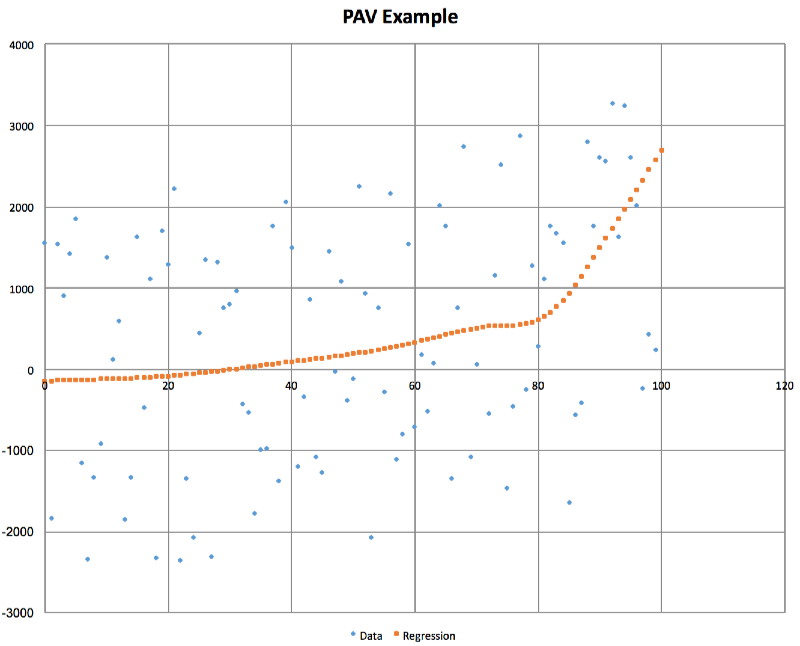
A picture is worth a thousand words
Here is the relationship that PAV extracts from some very noisy input data where there is an increasing relationship between x and y:
Features
- Smart linear interpolation between points and extrapolation outside the training data domain
- Fairly efficient implementation without compromizing code readability
- Will intelligently extrapolate to compute y for values of x greater or less than those used to build the PAV model
Usage example
use pav_regression::pav::{IsotonicRegression, Point};
// ..
let points = &[
Point::new(0.0, 1.0),
Point::new(1.0, 2.0),
Point::new(2.0, 1.5),
];
let regression = IsotonicRegression::new_ascending(points);
assert_eq!(
regression.interpolate(1.5), 1.75
);
For more examples please see the unit tests.
License
Released under the LGPL version 3 by Ian Clarke.
See also
- An earlier implementation of PAV for Kotlin/JVM by the same author: https://github.com/sanity/pairAdjacentViolators