tachyonix
| Crates.io | tachyonix |
| lib.rs | tachyonix |
| version | 0.3.1 |
| created_at | 2022-10-12 03:56:30.968566+00 |
| updated_at | 2024-09-08 20:14:40.036686+00 |
| description | A very fast asynchronous, multi-producer, single-consumer bounded channel. |
| homepage | |
| repository | https://github.com/asynchronics/tachyonix |
| max_upload_size | |
| id | 685870 |
| size | 85,750 |
 Serge Barral (sbarral)
Serge Barral (sbarral)
documentation
README
tachyonix
An asynchronous, multi-producer, single-consumer (MPSC) bounded channel that operates at tachyonic speeds.
This library is an offshoot of Asynchronix, an ongoing effort at a high performance asynchronous computation framework for system simulation.
No laws of physics were broken in the making of this library.

![]()
![]()
Overview
This is a no-frills async channel which only claim to fame is to be extremely
fast (see benchmarks), without taking any shortcuts on
correctness and implementation quality. Its performance mainly results from its
focus on the MPSC use-case and from a number of careful optimizations, among
which:
- aggressively optimized notification primitives for full-queue and
empty-queue events (the latter is courtesy of
diatomic-waker, a fast, spinlock-free alternative to
atomic-waker), - no allocation after channel creation except for blocked sender notifications,
- no spinlocks whatsoever, and no mutex in the hot path (the only mutex is a
std::sync::mutexused for blocked senders notifications), - underlying queue optimized for single receiver.
Usage
Add this to your Cargo.toml:
[dependencies]
tachyonix = "0.3.1"
Example
use tachyonix;
use futures_executor::{block_on, ThreadPool};
let pool = ThreadPool::new().unwrap();
let (s, mut r) = tachyonix::channel(3);
block_on( async move {
pool.spawn_ok( async move {
assert_eq!(s.send("Hello").await, Ok(()));
});
assert_eq!(r.recv().await, Ok("Hello"));
});
Limitations
The original raison d'être of this library was to provide a less idiosyncratic sibling to the channels developed for Asynchronix that could be easily benchmarked against other channel implementations. The experiment turned out better than anticipated so a slightly more fleshed out version was released for public consumption in the hope that others may find it useful. However, its API surface is intentionally kept small and it does not aspire to become much more than it is today. More importantly, it makes trade-offs that may or may not be acceptable depending on your use-case:
-
just like most other async channels except the MPSC channels in the
tokioandfuturescrates, fairness for blocked senders is not enforced: while the first sender blocked on a full channel is indeed notified first, it may still be outrun if another sender happens to be scheduled before; if your application requires better fairness guarantees, you should usetokio's orfutures's channels. -
just like most other async channels except the MPSC channels in the
futurescrate, the effective capacity of the channel decreases with each "forgotten" blocked sender (i.e. blocked senders which, for some reason, were not polled to completion but were not dropped either) and the channel will eventually deadlock if the effective capacity drops to zero; if this can happen in your application, you should usefutures's channels. -
just like most other async channel with the exception of
flume, its low-level primitives rely onunsafe(see dedicated section), -
zero-capacity channels (a.k.a. rendez-vous channels) are not supported.
Safety
Despite the focus on performance, implementation quality and correctness are the highest priority.
The library comes with a decent battery of tests, in particular for all low-level (unsafe) concurrency primitives which are extensively tested with Loom, complemented with MIRI for integrations tests. As amazing as they are, however, Loom and MIRI cannot formally prove the absence of data races so soundness issues are possible. You should therefore exercise caution before using it in mission-critical software until it receives more testing in the wild.
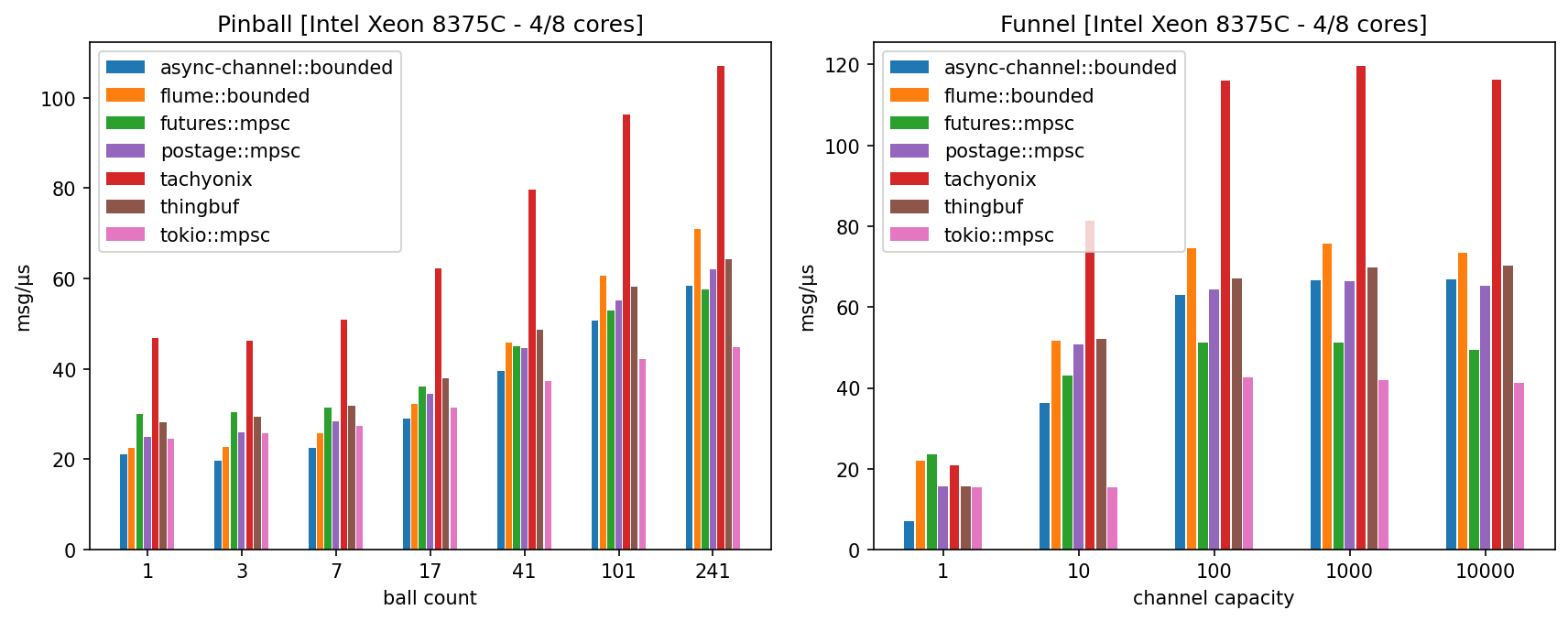
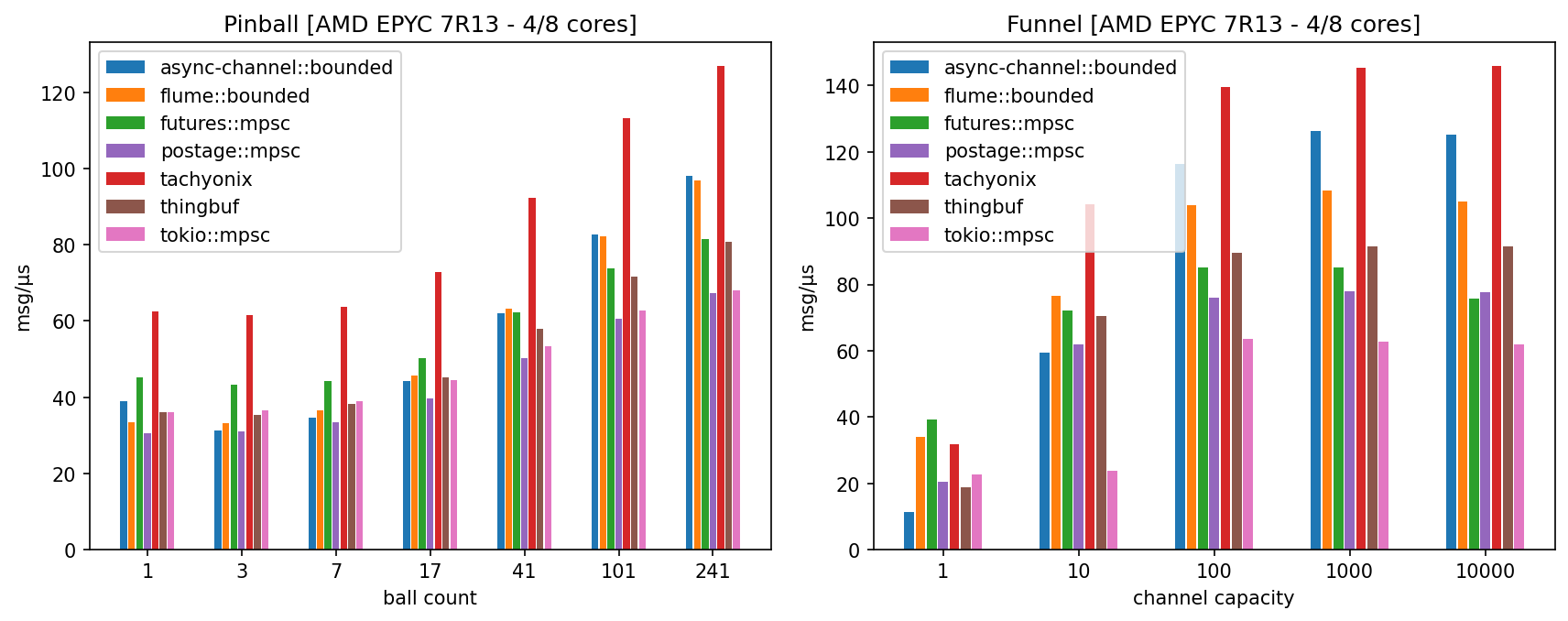
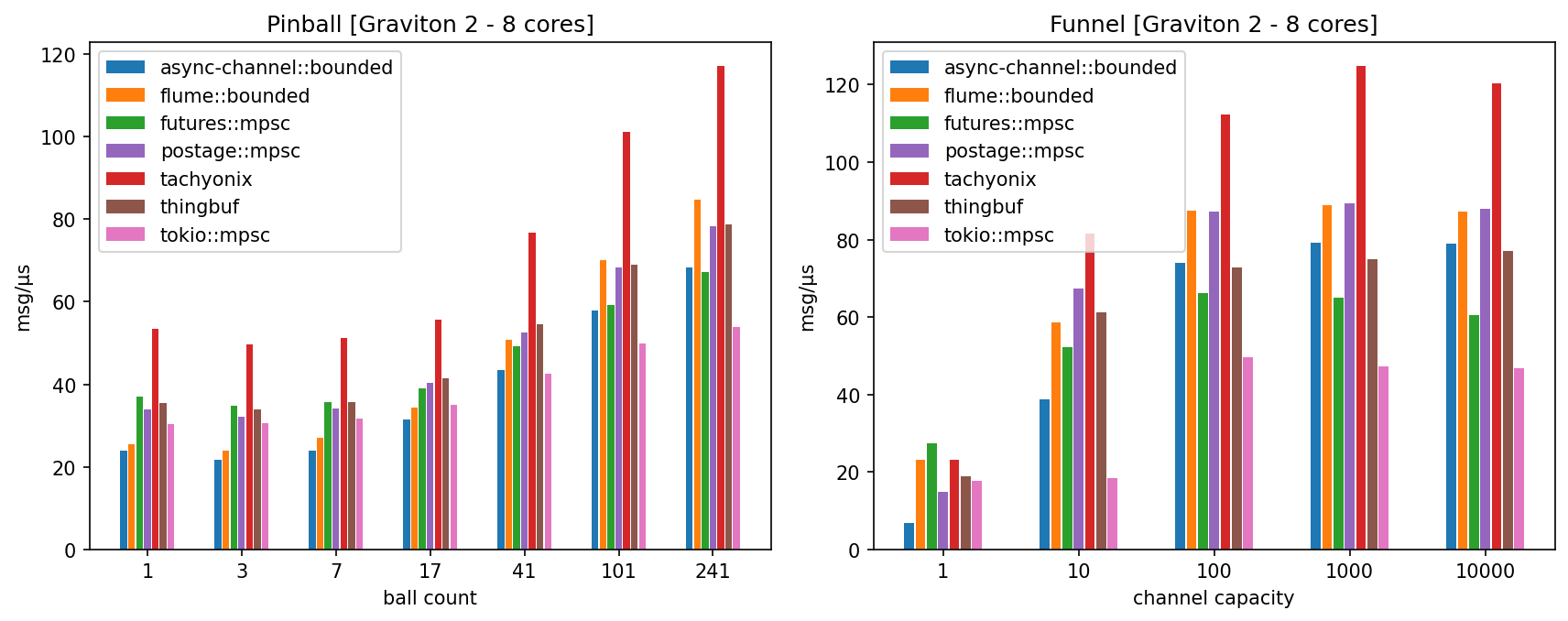
Benchmarks
Benchmarks overview
A custom benchmarking suite was implemented that can test a number of popular MPSC and MPMC channels with several executors (Tokio, async-std, smolscale and Asynchronix).
It contains at the moment 2 benchmarks:
- pinball: an upgraded version of the classical pin-pong benchmark where messages ("balls") perform a random walk between 13 vertices ("pins") of a fully connected graph; it is parametrized by the total number of balls within the graph,
- funnel: the most common MPSC benchmark where messages are sent in a tight loop from 13 senders to a unique receiver; it is parametrized by the channel capacity.
Each benchmark executes 61 instances of an elementary bench rig, which ensures that all executor threads are busy at nearly all times. The pinball benchmark is a relatively good proxy for performance in situations where channel receivers are often starved but senders are never blocked (i.e. the channel capacity is always sufficient).
Regardless of its popularity, the funnel benchmark is less realistic and less objective as it is sensitive not only to the absolute speed of enqueue, dequeue and notifications, but is also strongly affected by their relative speed and by other subtle details. Its extrapolation to real-life performance is rather debatable.
More information about these benchmarks can be found in the bench repo.
Benchmark results
Keep in mind that raw speed is not everything: every channel makes design choices and trade-offs (regarding e.g. unsafety, fairness, mpmc support, ...) which can have a significant impact on performance. Be sure to read the sections about limitations and safety.
The benchmarks were run on EC2 instances of comparable performance but different micro-architectures (Intel Ice Lake, AMD Zen 3, ARM Graviton 2). The reported performance is the mean number of messages per microsecond after averaging over 10 benchmark runs (higher is better).
The reported results were obtained with Tokio, which in practice was found
significantly faster than either async-std or smolscale. Asynchronix is faster
yet, but less relevant as a baseline as it is not meant for general-purpose
async programming.
EC2 c6i.2xlarge
EC2 c6a.2xlarge
EC2 c6g.2xlarge
License
This software is licensed under the Apache License, Version 2.0 or the MIT license, at your option.
Contribution
Unless you explicitly state otherwise, any contribution intentionally submitted for inclusion in the work by you, as defined in the Apache-2.0 license, shall be dual licensed as above, without any additional terms or conditions.